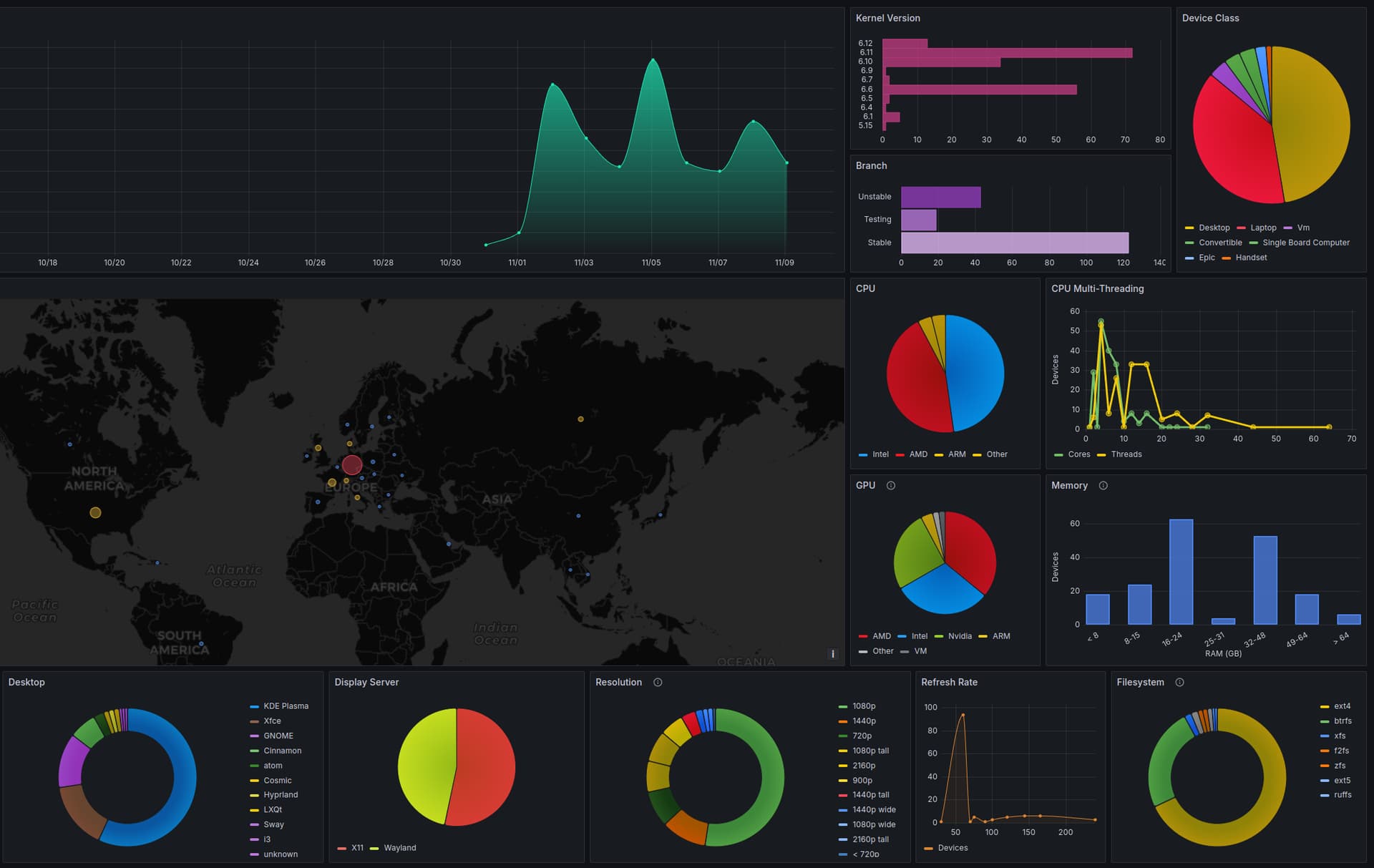
We’re currently testing a new open-source tool for Manjaro, that will help us with the development of Manjaro. It’s called MDD and it collects some anonymous and impersonal statistics about Manjaro systems.
You can check out the former development thread where some people posted their results to see what would be sent.
It’s good that you enable it but you should also mention that the KDE user feedback project was a big failure for several reasons. They could have just not done it to begin with.
NO ! it isn’t and @philm linked a yt-video that @philm favoured to think about it. this youtuber already stated out that your @romangg way of data-collecting is meant to be used as a fingerprint to every single user ! don’t spray sand into our eyes, data-collecting with giving a individual “machines-id” combined with a ip (even if it’s hashed) and a timestamp is a 100% fingerprint.
also, this is not a question of a “vote” from some users that have got a trust-level here at this forum cause we users with a trust-level are not legally powered to rule about any user that is using manjaro or want to do this in future. it is a legal question by law and nevertheless what you want to invent with your idea of “mdd”, it is not legal unless you get the individual and explicit permission of every individual user of manjaro. you have to get a individual permission and have to ask every single user independent, which is ending in a “license-aggreement” similar to ms-windows. otherwise this application is a dead-horse that is violating all and especially the european-data-security-laws. this is something that you have to figure out with @philm and all the other responsible persons at manjaro. this is a question for the legal-counsel and nothing to “vote” with some few privileded users of manjaro.
For me, there is no problem sharing metrics or statistics at all, as long as one can disable if he want it not, on fedora we had that bug report tool which to me was actually good and almost the same as the one in this proposition.
Also, users should consider the datas collected will actually help the distro to grow better and move in the right direction, known in Linux not every user do bug reports etc. this can help Devs to be aware of things and fix them so we can enjoy having good life
If during installation would be very obvious and clear that some sort of telemetry gets installed and enabled and the innocent reasons behind that would be briefly but clearly explained, and if it would be very clear and obvious and easy to disable it (during install and afterwards), I would have no problem at all.
With these conditions met in my mind, I voted for opt-out. Else I would vote for opt-in.
I understand you want to fingerprint every single installation, so that you can prove the size of your userbase (to gain financial support etc) - besides the technical reasons of course - and exactly for this reason I would participate. Maybe it would be a good idea to leave the IP and the exact timestamp (maybe add some random “noise” to the timestamp) out of this telemetry, in order to calm the privacy concerns of some people. I understand that a hashed value can’t directly lead to the original value, but I understand that some people think about crosschecks from different sources that could lead to the actual IP and have concerns. In the era of dynamic IPs and CGNAT maybe the IP (in any form - hashed or not) is of little value to fingerprinting for your causes.
A hashed IP address with salt can’t be reversed as a hash function is one-way. So from the stored value you can’t get the preimage since the preimage room is not enumerable.
What holds for IP addresses, holds even more so for machine IDs: a hashed machine ID can’t be reversed. And to be frank, if some threat actor got access to your blank machine ID, you got bigger problems.
Regarding the “fingerprint”. That is problematic when you can deanonymize a person through combination of multiple datasets or additional metadata. Since MDD doesn’t transmit any personal data about you, this is impossible.
The trust level limit is meant to make the vote results more reliable. Over 20k users have trust level 1 or above. So the result should be more than representative.
No, you don’t. Provide a source for your claim. This is only a question of ethics and what our users would prefer.
Finally turn down the rhetorical fervor. You can state your arguments without the drama.
I will stop commenting now cause it would just blow up my blood-pressure. you’re mdd is creating a individual machine-id that can be used in combination with the hashed-ip and the timestamp to fingerprint the individual user and still pretend this is not ? this is a terrible misleading of all users and i stop commenting before i start using emotional words… and again, this is not a question of a vote ! this is a question of legal-rights by law that you don’t want to respect and that’s a bad habit in a world where linux has the moral-compass to respect the user and his privacy.
i’m out
The argument is not wrong. But of course it depends on how the whole thing is implemented.
That’s not wrong either. However, the last part of the sentence is extremely important.
An IP consists of only 4 bytes. That is a data space of 0xFFFFFFFF. Anyone who has a memory that can store 0xFFFFFFFF times the hash can calculate all hashes in advance, provided they have the computing power for 0xFFFFFFFF times the hash calculation. That sounds very secure at first.
What if someone can distribute the work across 0xFF computers/processors?
Then 0xFFFFFF times the hash memory and 0xFFFFFF times the computing time is enough. That still seems secure
Or someone has access to 0xFFFF computers/processors?
Then 0xFFFF times the hash memory and 0xFFFF times the computing time is enough. That sounds like it could be a normal PC (e.g. in a botnet). 65,536 * 128 bytes (hash) is only 8MB
If you do the math, 0xFFFFFFFF hashes with 128 bytes are only 512 gigabytes. Yes, they are unique if a salt is used. But they are not impossible to calculate.
So a number with 4 bytes is enumerable, even if it is large. 0xFFFFFFFF= 4G. A salt does not change that if it is always the same for each IP.
The whole thing only becomes impossible if one of the following conditions is met:
the salt for each IP is different
the hash is stored so incompletely that duplicates arise
Then, even if all the hashes could be calculated, there is no clear way back.
Please also bear in mind that even I, who am not entrusted with such tasks, can immediately think of several ways to limit the data space of the IPs (and thus also the necessary computing time).
One possible solution is to calculate exactly one (!) unique ID on each PC, but only report back as many bits of its hash as are really needed to map 200k cleanly. If you accept that this will (very rarely) result in duplicates and that a single data set may then be lost, this guarantees that there will be no successful way back.
But I am convinced that you are already paying attention to this and are already getting advice from a specialist.
P.S. We say:
Food is cooked hot. But it is not eaten so hot.
No, it cannot and does not. It fingerprints the machine only, and only to the extent that it enables Manjaro to collect usage/installation statistics.
The machine-identifying data is also not shared with anyone outside of Manjaro, and no person-identifying data is sent, and can therefore also not be used.
and just to be clear, the fingerprint of a computer with a universal “machine-id” and combined with a “hashed” ip is a fingerprint that even low-brained intruders can and will hack.
this is a fundamental problem.
Let me see. If I parse this with the python script I wrote this morning.
a4ef99d7-ac59-5df1-a484-6c01d759e526
I get a person living in Germany, unfortunately my computer is not powerful enough to further break down that UUID. It will have to wait until I can afford that Quantum Computer.
… pretty good
so: my cover story, developed over years here on the forum, got you mighty close
It was probably: “Butter bei die Fische” that gave me away.