You would need to boot a live session and do it with gparted. So root is installed on sdb2 (serial disk b partition 2). So you would need to shrink sdb3, move to the right and expand sdb2 to the right.
No, that is the capacity of the root disk, the actual size of the file is 252 Bytes.
Open “Add/Remove Software” which is the pamac-manager. There you remove the snaps. On top you see in the middle “Installed”, click on it and on the left you see different types. There should also be “Snaps”, click on it. Now you have a list of all Snaps which are installed on your system. Uninstall them and probably replace them with native packages.
But in other words:
If i uninstall these files, my system won’t break, this are definitely no important system files - so in worst case i loose a programm and can reinstall it, am i right?
No you wont. Snap and also Flatpak deliver its own core libraries. So perfectly saying: If you use Snap or Flatpak Apps, then be aware that the libraries on the disk are at least doubled: Native and Snap/Flatpak Libraries. Sometimes more, that depends on the software you install.
Really, remove them with the snap tool, don’t do that manually. But you are right. Removing snaps is nothing critical to the system
The only thing that can possibly break is snap apps, those files have nothing to do with the rest of your system.
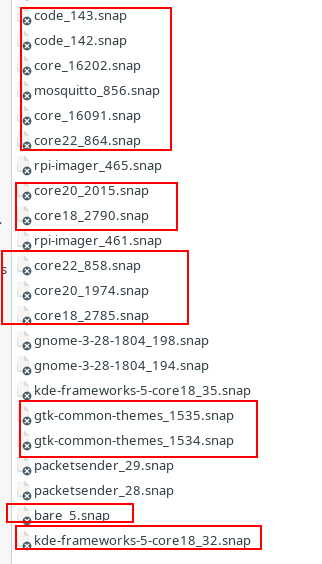
You don’t remember installing things like “core_1602.snap” because you didn’t, they were installed automatically because a snap app that you installed depended on them. This is why snaps take up so much space.
The general advice is to avoid snaps completely unless you really have no other choice. Flatpak is also a space hog but is preferred over snap. But always check the offical repository for native versions first, as in the case of rpi-imager. I see you also have VS Code installed as a snap. I use Code OSS which is the open-source version of VS Code and is in the offical repository (but there may be some gotchas there depending on what extensions you use - Visual Studio Code - ArchWiki).
If your file system is btrfs, you may want to ‘balance’ it.
The process requires free space, so you probably have to increase the file system temporarily a little – a usb stick will do.
Add it to the btrfs volume, do the balancing, remove it from the btrfs volume, and ONLY THEN you can disconnect it. If you do it before that, the filesystem is unusable.
If your storage is an SSD you most likely do NOT want to balance it.
But if you for some reason HAVE to balance it, make damn sure you do your research first and understand what a balance is doing.
Running balance without filters will take a lot of time as it basically move data/metadata from the whole filesystem and needs to update all block pointers. Balance — BTRFS documentation
If you run btrfs and timeshift f ex, the first thing you should check (if you start to run out of space) is that the snapshots are being deleted after x amount. Leftover snapshots can eat up a LOT of space if they are very old compared to brand new ones that take up almost no space (CoW filesystem).
The only reason could be flash degradation, but with the lifetimes of today’s ssds the average user will still have several decades of use with a weekly or monthly balance. (Of course, set filter and balance the metadata much less frequent.)
OP will have to do their reading, but that they should always do (unless a very specific advice was given).
Are you seriously asking me WHY not to cause COMPLETELY unnecessary rewrites, on a device that has a limited times of writes before it stops functioning?
I can turn it around. Why would you EVER need to re balance a filesystem that is not multi disk?!?
If you want to SIGNIFICANTLY shorten the lifespans of your SSD:s sure, go ahead, but advising other ppl to do it, heck no!
DO NOT DO THIS!
In short: Reorganize chunks and make space available again.
After time it gets fragmented, what is not a problem on a SSD, but after time it reduces available free space, what can be a problem. And don’t be confused with file fragmentation, which doesn’t produce less available space.
When you add a disk, you need to convert the disks with the balance command, but after that btrfs spread the data itself. Same goes here: balance reorganize chunks and make space available again, which would be not available due fragmentation.
To get a picture: A chunk is always 1GB in size. When you delete a file, it will not overwrite it, but write a new file into another chunk for example. If the file doesn’t fit in the free space of the chunk it will create a new chunk. Now the balance command searches for files and fill the chunks again, so that you have more space on the last chunk (or even eliminate unnecessary chunks). That way you don’t waste space. A half full chunk for example will count as a full chunk and therefore half of the space is not available, but allocated.
Always use filters when balancing. A full balance should be avoided.
I prefer to not think in All-Or-Nothing, Always-or-Never, Only-Good-or-Only-Bad categories. Found a quantitative approach more useful when dealing with real life.
To calculate the SSD lifespan, you can use the following formula: (Write cycles * Capacity) / (SSD factor * Data Written per year)
Consider a Samsung 850 PRO, TLC SSD, with a capacity of 1 TB.
Then,
Write cycles= 3,000
Capacity= 1 TB or 1,000 GB
SSD Factor: real amount of data to actual amount of data written= 5 consider)
Amount of data written to the drive per year= 1,500-2,000 GB (estimated)
Thus, the formula becomes: (3,000 * 1,000)/(5 * 1,750)
= 342 years
The drive cannot be guaranteed to be relied upon for 342 years. But based on these assumptions, the oxide layer of the SSD will last this long.
A joint study between Google and the University of Toronto[2016] covering drive failure rates on data servers. The study concluded that the physical age of the SSD, rather than the amount or frequency of data written, is the prime determiner in probability of data retention errors.
The Tech Report’s study[2014] on longevity between major brands. Among six brands of SSDs tested, only the Kingston, Samsung, and Corsair high-end drives managed to survive after writing over 1000 terabytes of data (one petabyte). The other drives failed at between 700 and 900 TBW. Two of the failed drives, Samsung and Intel, used the cheaper MLC standard, while the Kingston drive is actually the same model as the one that survived, only tested with a similar methodology. Conclusion: a ~250GB SSD can be expected to die sometime before one petabyte written — though two (or perhaps three) of the models exceeded that mark, it would be wise to plan a contingency in case your specific drive under-performs, even if it uses more expensive SLC memory.
Larger capacity SSDs, due to having more available sectors and more “room” to use before failing, should last longer in a predictable manner. For example, if a 250GB Samsung 840 MLC drive failed at 900 TBW, it would be reasonable to expect a 1TB drive to last for considerably longer, if not necessarily all the way to a massive 3.6 petabytes written.
Facebook publicly published an internal study[2015] (PDF link) of the lifespan of SSDs used in its corporate data centers. The findings were focused on the environmental conditions of the data centers themselves — for example, they came to the fairly obvious conclusion that extended proximity to high heat was damaging to an SSD’s lifespan. But the study also found that if an SSD doesn’t fail after its first major detectable errors, then it’s likely to last far longer than overly cautious software diagnostic software. Contradicting Google’s joint study, Facebook found that higher data write and read rates can significantly impact the lifespan of a drive, though it isn’t clear if the latter was controlling for the physical age of the drive itself. Conclusion: Except in cases of early total failure, SSDs are likely to last longer than indicated by early errors, and data vectors like TDW are likely to be overstated by software measurement because of system-level buffering.
Of course, all of those studies are looking at intense datacenter applications. The average home user won’t come anywhere close to that kind of utilization.
And that was about SSDs from seven to nine years ago.