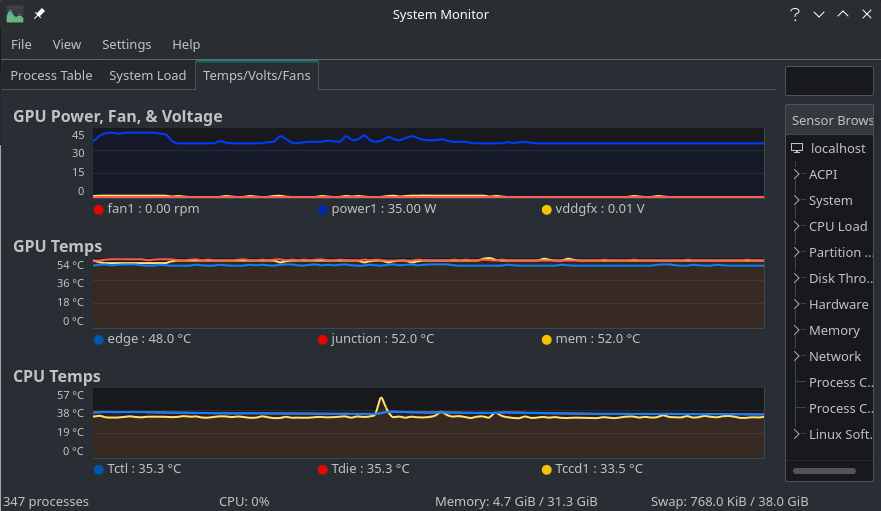
Yesterday I was playing with building shell scripts to gain visibility into my systems sensors, which included installing radeontop…
radeontop.sh
#!/bin/bash
konsole --hide-tabbar --hide-menubar -e radeontop
watchGPU.sh
#!/bin/bash
konsole -e sudo watch -n 0.5 cat /sys/kernel/debug/dri/0/amdgpu_pm_info
watchsensors.sh
#!/bin/bash
konsole -e watch -n 0.5 sensors
…and then I discovered psensor and settled into using just it and watchGPU.sh.
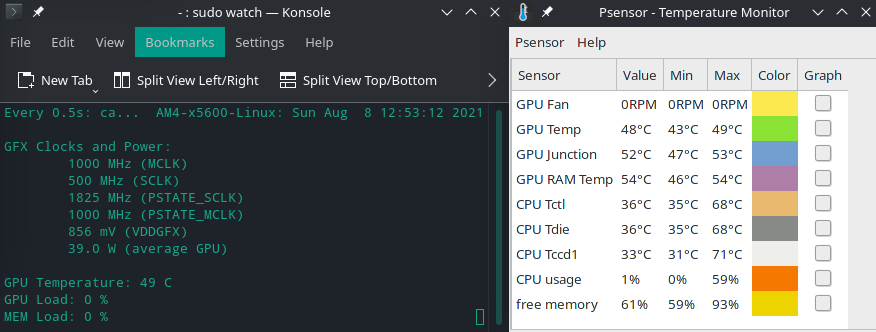
Potential red herring… somewhere along the line I recall finding a “stuck” terminal session that would not close and then I selected an option to kill the process. Before finally figuring out I needed to use konsole in my shell scripts (to launch a terminal window with my command) I was following examples that stated to use xterm (which did not work, command not found).
Things seemed to be going fine otherwise, until I decided I wanted to move my psensor pinned icon in the taskbar… I could “grab it” (saw a fist as it was “selected”) but it would not move it’s icon position.
I though that was weird and went to bed. This morning, the issue persisted and I thought maybe a reboot would be a good idea. Selected restart from the Manjaro Menu… and things got interesting…
- The initial “shutting” down sequence started with (what I assume to be) a “clean”
fsckreporting of the system drive - then I caught this flash of an error that I think indicated it was (I’m paraphrasing)
unable to unmount user 1000… me - seeing this error was very brief as the system rebooted
- The initial power-up sequence started with (what I assume to be) a “clean”
fsckreporting of the system drive… and then a pause - Then I heard my Software RAID array spin up and thought… oh right,
fsckwill look at the array every 4 boots… today must be the day - the mechanical disks stopped clacking… more pause
- then the timeouts/failures started rolling in as it worked through my
fstabmounts
- Trying to make sense of the
emergency modedirections… I first typed inexitto try reboot (soft) normally - after a pause, it reprompted for another choice (previous choice failed?)… this time I typed
systemctl rebootto try restart… and after more pause (in this screen) I powered down for a hard reboot - I rebooted normally on the hard reboot, and was finally able to reposition my
psensortaskbar icon
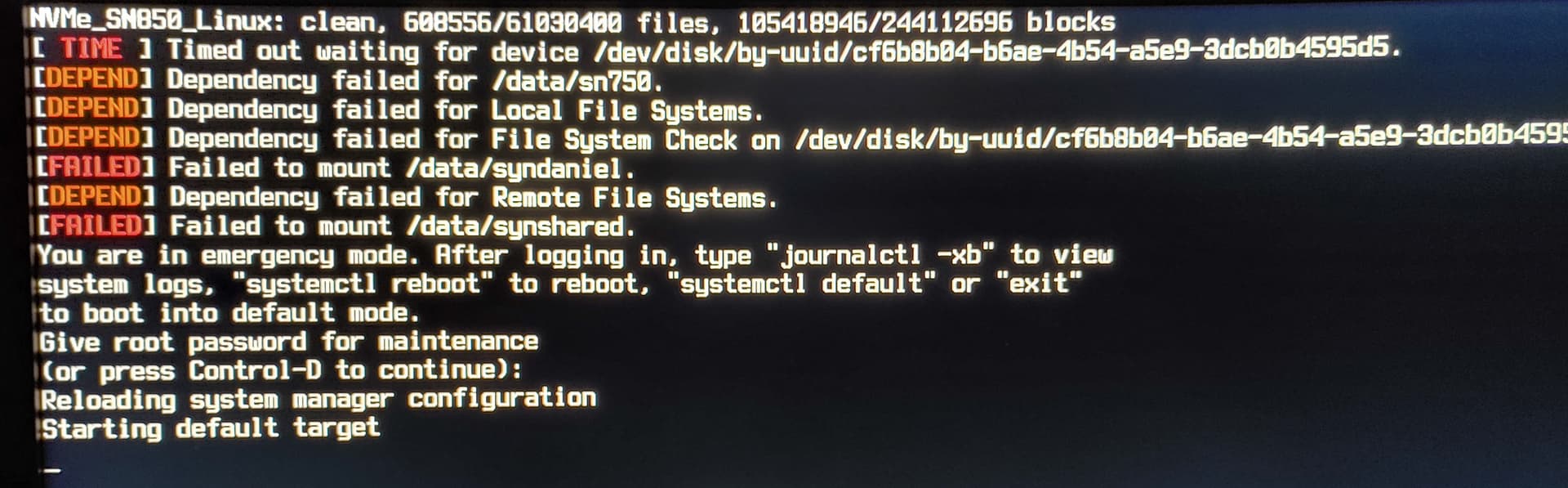
All looks fine/normal now, but I can’t help but wonder…
- what in the world went wrong?
- And is there a relationship between the “locked taskbar”, the unmountable user, and the initial soft reboot timeouts?
- Might the locked terminal session I aborted have been a sign?
- what might have been “lingering” in the soft reboot that the hard reboot clearer or worked around?
Couple other peices of information for reference…
- I think my SN750 is fine…
$ sudo smartctl --all /dev/nvme1n1
smartctl 7.2 2020-12-30 r5155 [x86_64-linux-5.13.5-1-MANJARO] (local build)
Copyright (C) 2002-20, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Number: WDS100T3X0C-00SJG0
Serial Number: 192725805856
Firmware Version: 102000WD
PCI Vendor/Subsystem ID: 0x15b7
IEEE OUI Identifier: 0x001b44
Total NVM Capacity: 1,000,204,886,016 [1.00 TB]
Unallocated NVM Capacity: 0
Controller ID: 8215
NVMe Version: 1.3
Number of Namespaces: 1
Namespace 1 Size/Capacity: 1,000,204,886,016 [1.00 TB]
Namespace 1 Formatted LBA Size: 512
Namespace 1 IEEE EUI-64: 001b44 8b4472fa2a
Local Time is: Sun Aug 8 12:30:55 2021 CDT
Firmware Updates (0x14): 2 Slots, no Reset required
Optional Admin Commands (0x0017): Security Format Frmw_DL Self_Test
Optional NVM Commands (0x001f): Comp Wr_Unc DS_Mngmt Wr_Zero Sav/Sel_Feat
Log Page Attributes (0x02): Cmd_Eff_Lg
Maximum Data Transfer Size: 128 Pages
Warning Comp. Temp. Threshold: 80 Celsius
Critical Comp. Temp. Threshold: 85 Celsius
Namespace 1 Features (0x02): NA_Fields
Supported Power States
St Op Max Active Idle RL RT WL WT Ent_Lat Ex_Lat
0 + 6.00W - - 0 0 0 0 0 0
1 + 3.50W - - 1 1 1 1 0 0
2 + 3.00W - - 2 2 2 2 0 0
3 - 0.1000W - - 3 3 3 3 4000 10000
4 - 0.0025W - - 4 4 4 4 4000 45000
Supported LBA Sizes (NSID 0x1)
Id Fmt Data Metadt Rel_Perf
0 + 512 0 2
1 - 4096 0 1
=== START OF SMART DATA SECTION ===
SMART overall-health self-assessment test result: PASSED
SMART/Health Information (NVMe Log 0x02)
Critical Warning: 0x00
Temperature: 38 Celsius
Available Spare: 100%
Available Spare Threshold: 10%
Percentage Used: 0%
Data Units Read: 42,643,866 [21.8 TB]
Data Units Written: 32,669,419 [16.7 TB]
Host Read Commands: 331,584,942
Host Write Commands: 524,770,081
Controller Busy Time: 1,112
Power Cycles: 51
Power On Hours: 14,437
Unsafe Shutdowns: 11
Media and Data Integrity Errors: 0
Error Information Log Entries: 1,440
Warning Comp. Temperature Time: 0
Critical Comp. Temperature Time: 0
Error Information (NVMe Log 0x01, 16 of 256 entries)
No Errors Logged
-
/etc/fstabcontents
$ cat /etc/fstab
# /etc/fstab: static file system information.
#
# Use 'blkid' to print the universally unique identifier for a device; this may
# be used with UUID= as a more robust way to name devices that works even if
# disks are added and removed. See fstab(5).
#
# <file system> <mount point> <type> <options> <dump> <pass>
UUID=B4AB-4594 /boot/efi vfat umask=0077 0 2
UUID=5d67a7c6-6cdf-446d-92f6-b7be1f0fb13d / ext4 defaults,noatime 0 1
UUID=cf6b8b04-b6ae-4b54-a5e9-3dcb0b4595d5 /data/sn750 ext4 defaults,noatime 0 2
UUID=1bbb2871-a304-4482-82e1-b4fda98cfeab /data/evo840 ext4 defaults,noatime 0 2
UUID=6487110f-670a-4bac-b88f-e422fb107071 /data/raid1 ext4 defaults,noatime 0 2
192.168.100.140:/volume1/Daniel /data/syndaniel nfs rsize=8192,wsize=8192,timeo=14,_netdev 0 0
192.168.100.140:/volume1/Shared /data/synshared nfs rsize=8192,wsize=8192,timeo=14,_netdev 0 0
/swapfile none swap defaults 0 0
- post hard reboot
journalctl -xb
$ journalctl -xb
-- Journal begins at Tue 2021-07-13 15:47:15 CDT, ends at Sun 2021-08-08 12:37:43 CDT. --
Aug 08 11:23:01 AM4-x5600-Linux kernel: Linux version 5.13.5-1-MANJARO (builduser@LEGION) (gcc (GCC) 11.1.0, GNU ld (GNU Binutils) 2.36.1) #>
Aug 08 11:23:01 AM4-x5600-Linux kernel: Command line: BOOT_IMAGE=/boot/vmlinuz-5.13-x86_64 root=UUID=5d67a7c6-6cdf-446d-92f6-b7be1f0fb13d rw>
Aug 08 11:23:01 AM4-x5600-Linux kernel: x86/fpu: Supporting XSAVE feature 0x001: 'x87 floating point registers'
Aug 08 11:23:01 AM4-x5600-Linux kernel: x86/fpu: Supporting XSAVE feature 0x002: 'SSE registers'
Aug 08 11:23:01 AM4-x5600-Linux kernel: x86/fpu: Supporting XSAVE feature 0x004: 'AVX registers'
Aug 08 11:23:01 AM4-x5600-Linux kernel: x86/fpu: Supporting XSAVE feature 0x200: 'Protection Keys User registers'
Aug 08 11:23:01 AM4-x5600-Linux kernel: x86/fpu: xstate_offset[2]: 576, xstate_sizes[2]: 256
Aug 08 11:23:01 AM4-x5600-Linux kernel: x86/fpu: xstate_offset[9]: 832, xstate_sizes[9]: 8
Aug 08 11:23:01 AM4-x5600-Linux kernel: x86/fpu: Enabled xstate features 0x207, context size is 840 bytes, using 'compacted' format.
Aug 08 11:23:01 AM4-x5600-Linux kernel: BIOS-provided physical RAM map:
Aug 08 11:23:01 AM4-x5600-Linux kernel: BIOS-e820: [mem 0x0000000000000000-0x000000000009ffff] usable
Aug 08 11:23:01 AM4-x5600-Linux kernel: BIOS-e820: [mem 0x00000000000a0000-0x00000000000fffff] reserved
Aug 08 11:23:01 AM4-x5600-Linux kernel: BIOS-e820: [mem 0x0000000000100000-0x0000000009d81fff] usable
Aug 08 11:23:01 AM4-x5600-Linux kernel: BIOS-e820: [mem 0x0000000009d82000-0x0000000009ffffff] reserved
Aug 08 11:23:01 AM4-x5600-Linux kernel: BIOS-e820: [mem 0x000000000a000000-0x000000000a1fffff] usable
Aug 08 11:23:01 AM4-x5600-Linux kernel: BIOS-e820: [mem 0x000000000a200000-0x000000000a20dfff] ACPI NVS
Aug 08 11:23:01 AM4-x5600-Linux kernel: BIOS-e820: [mem 0x000000000a20e000-0x00000000cb03bfff] usable
Aug 08 11:23:01 AM4-x5600-Linux kernel: BIOS-e820: [mem 0x00000000cb03c000-0x00000000cb03cfff] reserved
Aug 08 11:23:01 AM4-x5600-Linux kernel: BIOS-e820: [mem 0x00000000cb03d000-0x00000000cb0a0fff] usable
Aug 08 11:23:01 AM4-x5600-Linux kernel: BIOS-e820: [mem 0x00000000cb0a1000-0x00000000cb0a1fff] reserved
Aug 08 11:23:01 AM4-x5600-Linux kernel: BIOS-e820: [mem 0x00000000cb0a2000-0x00000000dad0bfff] usable
Aug 08 11:23:01 AM4-x5600-Linux kernel: BIOS-e820: [mem 0x00000000dad0c000-0x00000000db068fff] reserved
Aug 08 11:23:01 AM4-x5600-Linux kernel: BIOS-e820: [mem 0x00000000db069000-0x00000000db0ccfff] ACPI data
Aug 08 11:23:01 AM4-x5600-Linux kernel: BIOS-e820: [mem 0x00000000db0cd000-0x00000000dcbccfff] ACPI NVS
Aug 08 11:23:01 AM4-x5600-Linux kernel: BIOS-e820: [mem 0x00000000dcbcd000-0x00000000ddb56fff] reserved
Aug 08 11:23:01 AM4-x5600-Linux kernel: BIOS-e820: [mem 0x00000000ddb57000-0x00000000ddbfefff] type 20
Aug 08 11:23:01 AM4-x5600-Linux kernel: BIOS-e820: [mem 0x00000000ddbff000-0x00000000deffffff] usable
Aug 08 11:23:01 AM4-x5600-Linux kernel: BIOS-e820: [mem 0x00000000df000000-0x00000000dfffffff] reserved
Aug 08 11:23:01 AM4-x5600-Linux kernel: BIOS-e820: [mem 0x00000000f0000000-0x00000000f7ffffff] reserved
Aug 08 11:23:01 AM4-x5600-Linux kernel: BIOS-e820: [mem 0x00000000fd200000-0x00000000fd2fffff] reserved
Aug 08 11:23:01 AM4-x5600-Linux kernel: BIOS-e820: [mem 0x00000000fd400000-0x00000000fd5fffff] reserved