Woa,
I have checked long enough today. The result is that 1 of 4 RAMs is faulty. Rest 3 RAMs are fine after 15 times copies of the zip 15GB, all checksums are passed, no error.
Mainboard and CPU are not faulty.
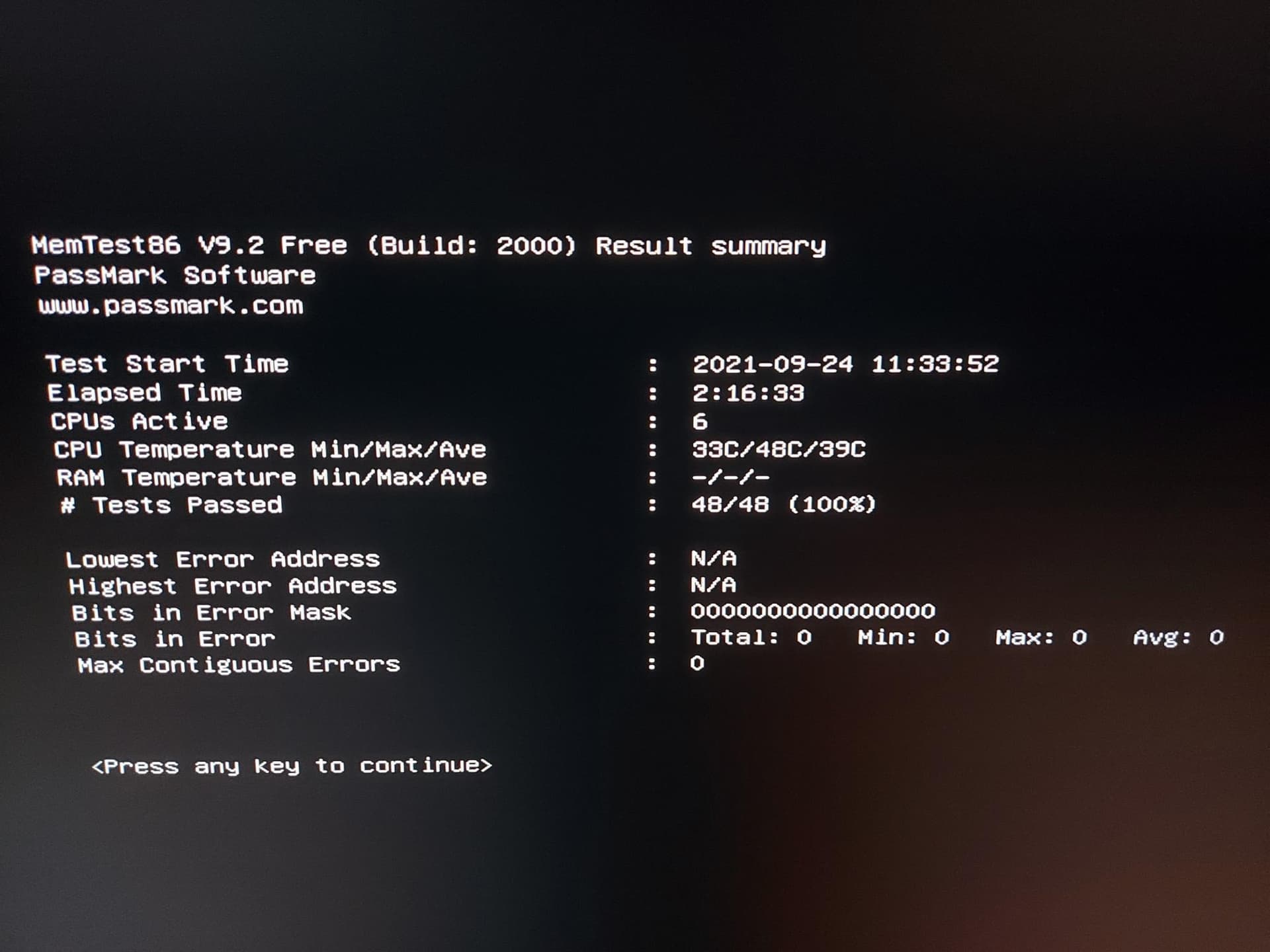
memtest86+ was joke to say that everything of RAM was passed.
I have to thank BTRFS for warning me earlier why I/O reading failed,
EXT4 did not warn me without noticing.
ZFS and Btrfs have built-in data integrity checks. Ext4, XFS, F2FS do not.
I’ve read some stories that memtests are most reliable and trustworthy when testing one stick at a time. I should have mentioned this much earlier, and I apologize I did not. It would have been tedious, to check full passes one at a time, but definitely more accurate.
However now you can brag about doing your own process of elimination and diagnosis to find the root cause of a dangerous problem.
How long have you been using this computer? It’s very likely that much of the data you saved, copied, backed up, etc, is corrupt (corrupt in the sense that it does not 100% reflect how the file should exist on storage, whether from a new creation, modification, or copy.)
I have been buying this RAM for this computer since January 2021 without noticing that it is damaged. Then I bought the new SSD 1 month ago and installed new Manjaro on this SSD with full BTRFS.
I have checked my current used data from January to today. Many of these data are not important for me.
I’m glad too. At least with faulty hardware, you can pull it out or replace it. But with a filesystem? It’s nail-biting levels of unnerving where you’re not quite sure if it’s misbehaving or trying to warn you.
Sadly, ECC RAM is pricey because there’s no real “consumer” market: it’s primarily produced for enterprise. In a better world, it would have been a feasible option for home users and would be much more accessible and affordable.
I only use ECC (and ZFS!) for my NAS server, however, since it’s my bastion for archiving data and holding backups of known good copies.
Did you determine that by hash sum checking of 15 copies of the same file while using that single faulty RAM module and on some of the copies hash sums was not the same with other copies?
And you checked every of other 3 RAM modules with that 15 file copies test and their hash sums was the same?
Yes, and many different hash sums for the same file too, it looks so wrong calculation. I think CPU loaded some corrupt addresses or values from this RAM.
We are the developers for MemTest86 (not the ‘+’ version, which is no longer unmaintained), but the original version, which you used. A user directed our attention to this post.
The version of MemTest86 you used was slightly old, but we don’t think it would have changed the outcome. We are wondering if the error was in fact linked to either.
A) Row hammer bit flips. These are in fact memory failures, but the test case for row hammer is somewhat artificial and should nearly never occur in real life applications.
B) Also linked to CPU load / system temperature. MemTest86 doesn’t load the CPU much. SHA1 calculations would likely heat the system more that simple read / write testing.
C) Maybe booting into the O/S changed some settings /timings / fan speeds /EMI environment which made the RAM error more obvious. This isn’t very common however.
Anyway our thought was this. Can we buy the faulty pair of RAM sticks from you and we can do some more in depth testing on them in a few different systems (assuming they were in a pair). With a view to improving the fault reporting in Memtest86.
I have already checked 2 days ago. My system with 1 faulty RAM without other 3 RAMs has less calculation errors and copy errors than the system with all 4 RAMs together.
Very difference of SHA1 calculation errors between 1 faulty RAM and 4 RAMs
→ 1 faulty RAM: ←
If SHA1 calculation error for the same zip file has appeared first time, then check SHA1 again, most likely no error, but luck. Probably 1 out of 20 repetitions of SHA1 check is wrong. But every wrong SHA1 result is different.
Repeat copy (read and write) has more errors than SHA1 checks (read only) !? (-> I do not yet know whether writing is also wrong when copying)
→ 1 faulty RAM with 3 RAMs together ←
When SHA1 calculation error for this same zip appeared first time, then check calculation again, always different wrong results of SHA1 for many same repetitions of check. They are worse than the faulty RAM alone.
Repetition of copy is much worse.
That is why I think one faulty RAM has spread some faulty values to other 3 RAMs, like error propagation.
But all wrong values in cache of RAMs are not cleared until power off PC.
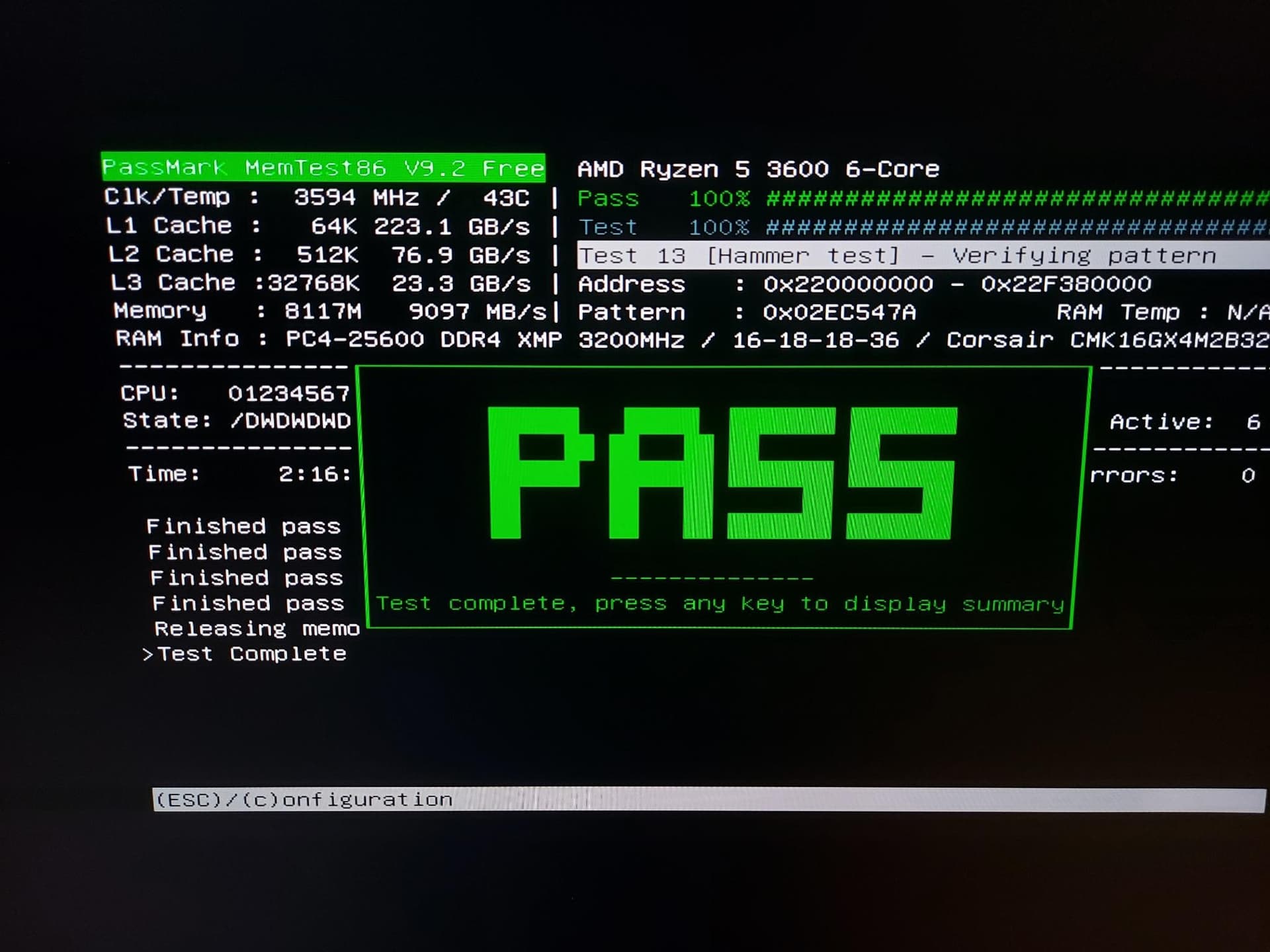
Today I just tried to test the faulty RAM with the last version of MemTest86 v9.2 from the official website MemTest86 - Download now!. The result comes in reality, if you want to know:
@PassMark, it is possible testing one RAM stick at a time is more likely to avoid false negatives?
i.e, If there’s one faulty RAM stick among a kit of four, testing each one individually, plugged in by itself (without the other three), is more likely to find the faulty RAM stick, rather than testing with all four concurrently installed?
…or while much faster (dual or more channel) testing, may be the faulty RAM module needs to be marked somehow in a testing log: by serial number of somehow else to user can recognize faulty physical module after testing.
But @winnie and me are going a bit off-topic:
this thread about suspecting RAM module to be damaged but currently it is not recognized by using testing methodology of the used tests to let PassMark to investigate the case to improve their tests or to conclude that the problem source is not in that RAM module and tests used.
If that would be impossible because of your low reputation on this site, flag the post and anyone of the moderator group will elevate your privilege if you link to this post…
My apologies for changing the solution to this post but that was the one leading to the solution, not your verification of the lead as that one will lead to other users having the same issue as you have to resolve their problem.
However, if you disagree with my choice, please feel free to take any other answer as the solution to your question or even remove the solution altogether: You are in control! (If you disagree with my choice, just send me a personal message and explain why I shouldn’t have done this or or if you agree)

 or
or  if you agree)
if you agree)