@winnie
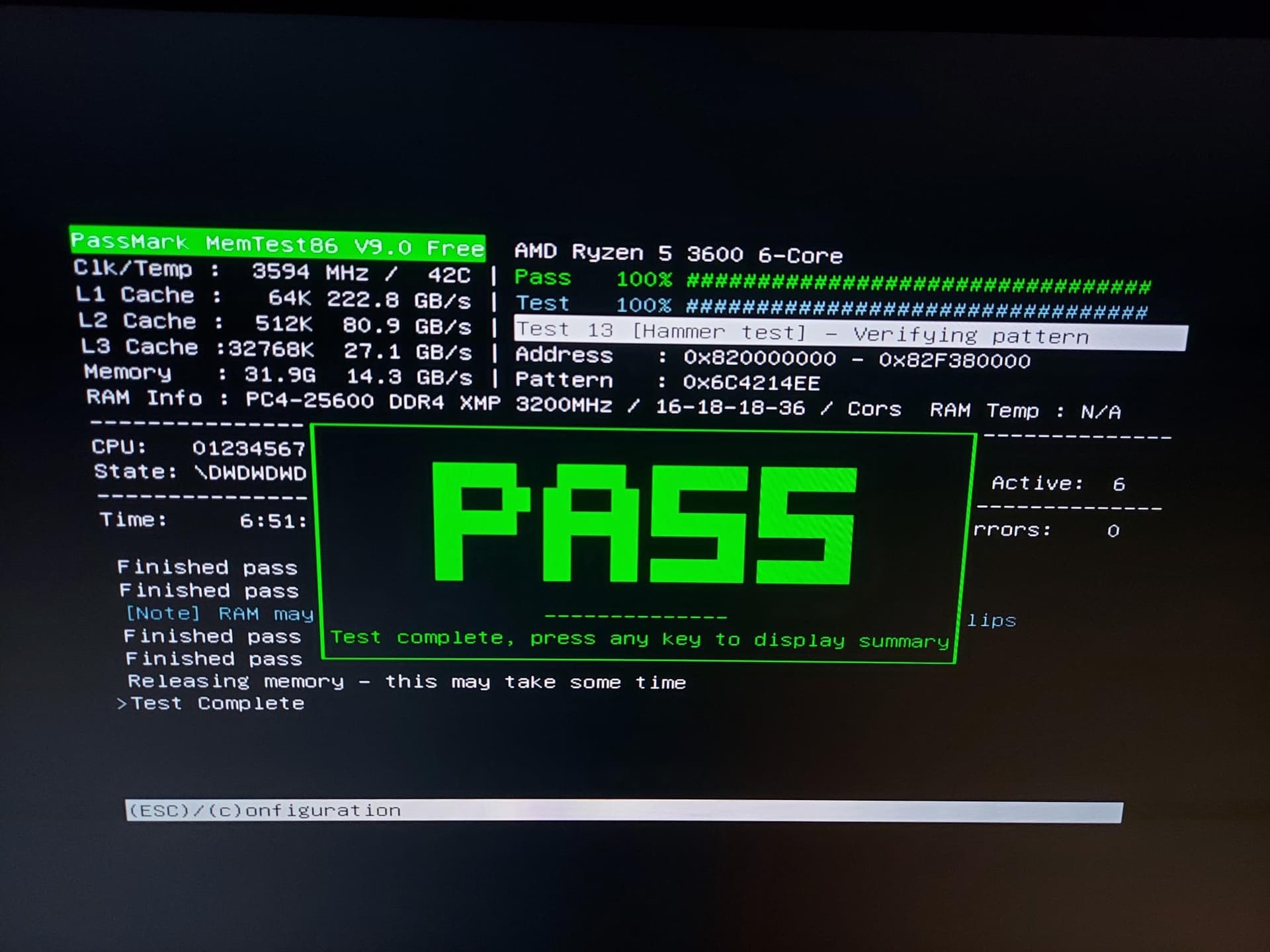
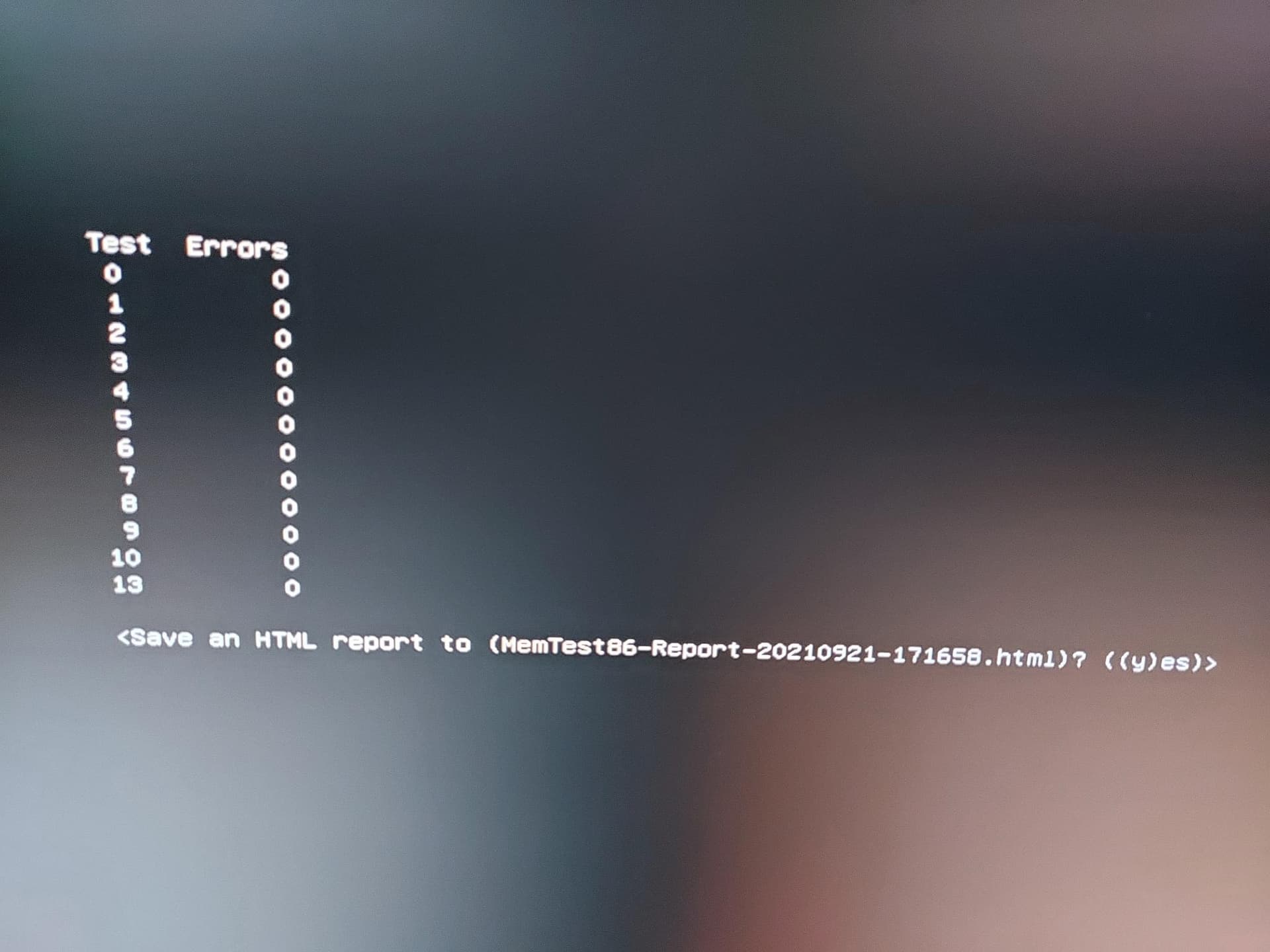
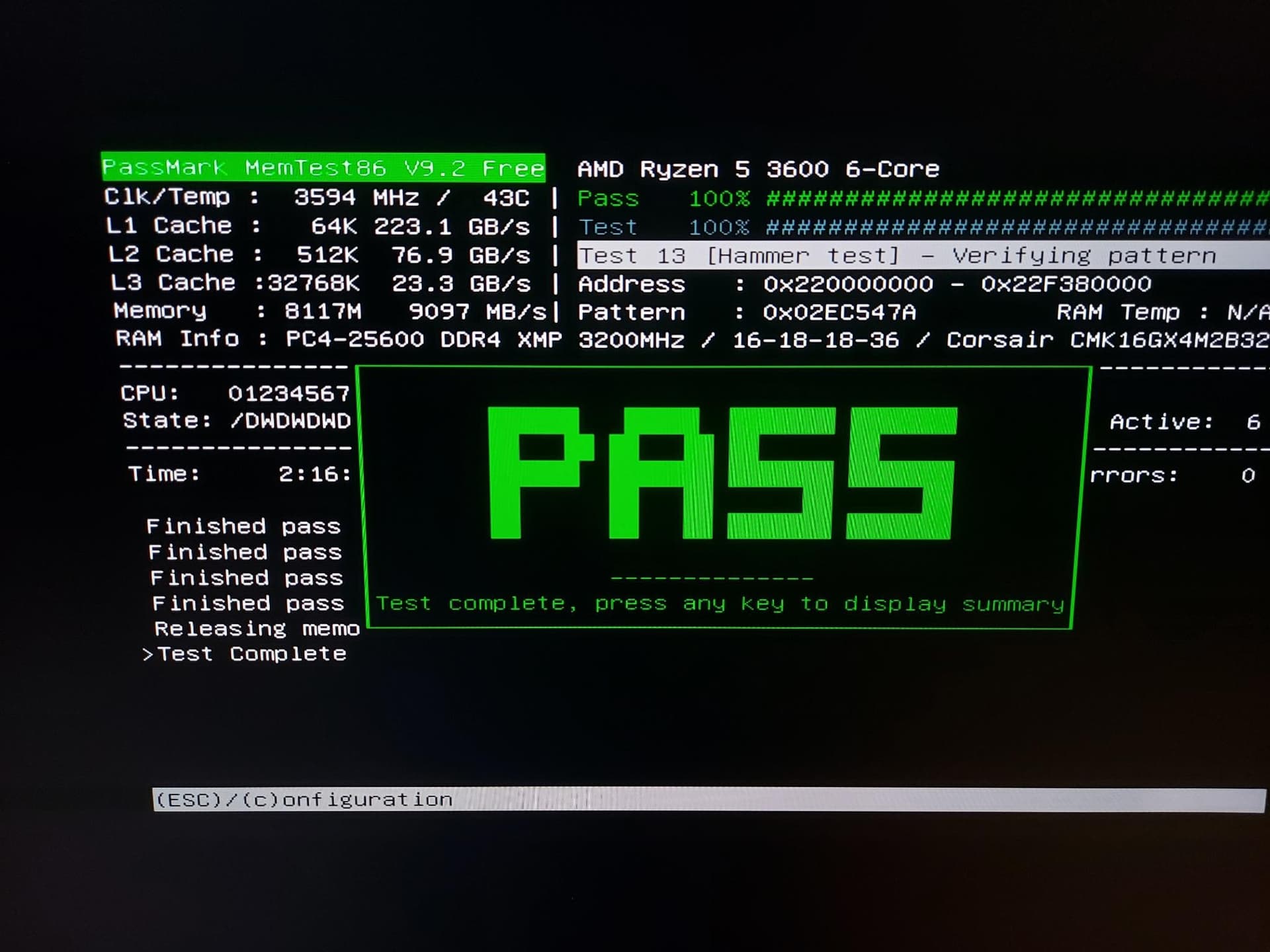
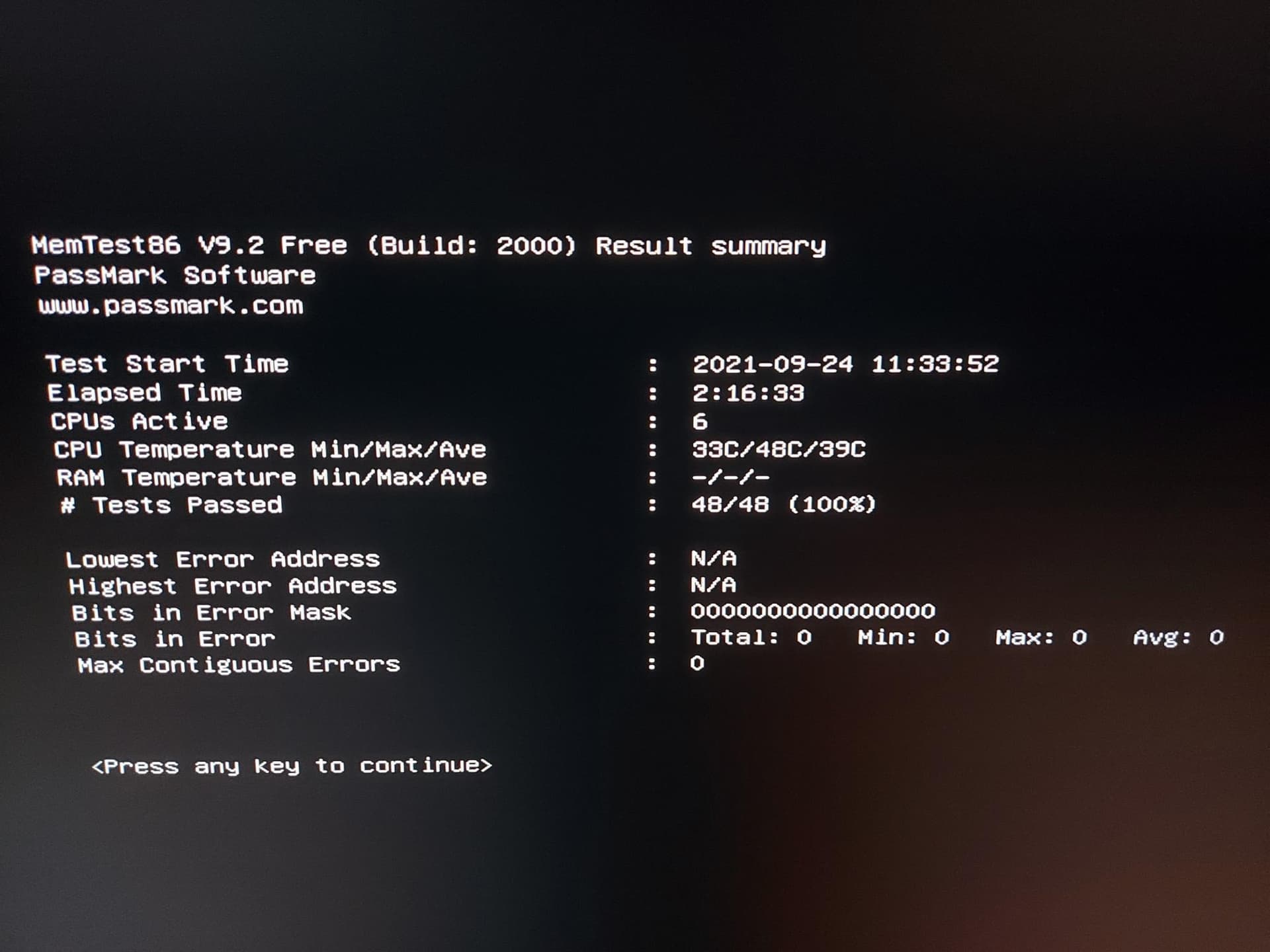
memtest86-efi has completely tested after 7 hours. Everything is OK. 
But it showed [Note] RAM may be vulnerable to high frequency row hammer bit flips.
I found another problem. Not only copy errors, but also reading or CPU calculation errors too?
The same file test1.zip has many different checksum. 
 I did not change it.
I did not change it.
❯ sha1sum test1.zip
e9bb2bfc90ad058aa73154cce4814fd744cc11f8 test1.zip # Failed
❯ sha1sum test1.zip
ea1127716ab44a6b74507ec7c503409ae5e84f21 test1.zip # Failed
❯ sha1sum test1.zip
bdb8b9098a3b0fc7055f20af586457156023be2d test1.zip # Failed
❯ sha1sum test1.zip
0d7f28ed306c395baa0ec9436a356672843e9021 test1.zip # Failed
on my old SSD.
❯ sha1sum test1.zip
b35cd8b5df411a5b20ac456f67b95f089502919f test1.zip # OK
❯ sha1sum test1.zip
b35cd8b5df411a5b20ac456f67b95f089502919f test1.zip # OK
❯ sha1sum test1.zip
f48ea7c128e8f7f892636f8c05623a243ec09c01 test1.zip # Failed
❯ sha1sum test1.zip
3f2b211343854f8d2faf70800e76a86ff75106a9 test1.zip # Failed
❯ sha1sum test1.zip
f4ec8624a5ae5f61bd3b7e95b898dc841436fd6e test1.zip # Failed
on my new SSD.
Both SSDs are affected on the same device 1.
I checked the same file 15GB in my USB stick 64GB (EXT4) on my device 1, it shows different checksums too.
But I checked this USB stick on my other device 2, then no issue → The same file shows always the same checksum.
I checket the zip on Windows 10 on the same device 1, but only data transfer or copy has the problem too, but many copies are correct, few are incorrect, but checksum is always the same for individual zip, but on Linux it shows random different checksums.
The device 1 is currently running with mprime. I see many were passed.
I checked the zip file with the help of Manjaro Live USB on the device 1, the same issue.
I stop mprime now. I try to set the mainboard BIOS setting, for example AMD-V is switched off. I remove 3 of 4 RAMs, then I see if it works.