That could be, if Zip compression initially wrote data to the faulty SSD or the faulty file system without info/warning, but BTRFS can stop copying the broken file earlier when I want to transfer it to backup disk. Not bad. ![]()
I checked smartctl before copy.
❯ sudo smartctl -A /dev/nvme0n1
=== START OF SMART DATA SECTION ===
SMART/Health Information (NVMe Log 0x02)
Critical Warning: 0x00
Temperature: 52 Celsius
Available Spare: 100%
Available Spare Threshold: 5%
Percentage Used: 1%
Data Units Read: 9.541.220 [4,88 TB]
Data Units Written: 5.187.998 [2,65 TB]
Host Read Commands: 22.832.335
Host Write Commands: 34.318.571
Controller Busy Time: 170
Power Cycles: 233
Power On Hours: 272
Unsafe Shutdowns: 3
Media and Data Integrity Errors: 0
Error Information Log Entries: 354
Warning Comp. Temperature Time: 0
Critical Comp. Temperature Time: 0
Then I copied the same MEGA zip 4 times in my disk.
❯ cp MEGA.zip ~/Desktop/MEGA_copy.zip # No issue
❯ cp MEGA.zip ~/Desktop/MEGA_copy1.zip # No issue
❯ cp Desktop/MEGA_copy.zip ~/Downloads # No issue
❯ cp Desktop/MEGA_copy1.zip ~/Downloads # Failed
cp: error reading 'MEGA_copy1.zip': Input/output error
1 of 4 copy failed.
That means, my SSD is damaged after 1 month. 
I checked smartctl after the failed copy again:
❯ sudo smartctl -A /dev/nvme0n1
=== START OF SMART DATA SECTION ===
SMART/Health Information (NVMe Log 0x02)
Critical Warning: 0x00
...
Media and Data Integrity Errors: 0
Error Information Log Entries: 354 # The same number
Warning Comp. Temperature Time: 0
Critical Comp. Temperature Time: 0
It did not change “Error Information Log Entries”
I know it will count up after restart. It has nothing to do with the issue of copy.
I checked nvme:
❯ sudo nvme error-log /dev/nvme0n1
Error Log Entries for device:nvme0n1 entries:63
.................
Entry[ 0]
.................
error_count : 354
sqid : 0
cmdid : 0x19
status_field : 0x2002(INVALID_FIELD: A reserved coded value or an unsupported value in a defined field)
phase_tag : 0
parm_err_loc : 0x28
lba : 0
nsid : 0
vs : 0
trtype : The transport type is not indicated or the error is not transport related.
cs : 0
trtype_spec_info: 0
.................
Entry[ 1]
.................
error_count : 0
sqid : 0
cmdid : 0
status_field : 0(SUCCESS: The command completed successfully)
phase_tag : 0
parm_err_loc : 0
lba : 0
nsid : 0
vs : 0
trtype : The transport type is not indicated or the error is not transport related.
cs : 0
trtype_spec_info: 0
.................
...
nvme and smartctl can not detect that my SSD’s blocks are damaged?
The return of the damaged SSD was confirmed after the business contact today. I will get the refund.
I misunderstood that the SSD is guilty, but BTRFS is.
I have done enough testing BTRFS vs. EXT4 on the same partition “nvme1n1p5” in my other old SSD today.
-
I created new partition 200 GB with BTRFS first.
-
I checked
badblockto determine which block is bad:
❯ sudo badblocks -v /dev/nvme1n1p5 > Desktop/badsectors.txt
Checking blocks 0 to 204799999
Checking for bad blocks (read-only test):
done
Pass completed, 0 bad blocks found. (0/0/0 errors)
There is no bad block in this partition in the old SSD.
- I tested many same copies of the same zip file 15 GB on BTRFS.
/run/media/zesko/Test ❯ cp test1.zip test2.zip # OK
/run/media/zesko/Test ❯ cp test2.zip test3.zip # OK
/run/media/zesko/Test ❯ cp test3.zip test4.zip # Failed
cp: error reading 'test3.zip': Input/output error
Oh, the same error appeared because test3.zip is the broken file.
❯ journalctl -b -p 3
-- Journal begins at Tue 2021-08-17 19:59:59 CEST, ends at Tue 2021-09-21 13:55:23 CEST. --
Sep 21 13:55:23 zesko kernel: BTRFS error (device nvme1n1p5): bdev /dev/nvme1n1p5 errs: wr 0, rd 0, flush 0, corrupt 8, gen 0
Sep 21 13:55:23 zesko kernel: BTRFS error (device nvme1n1p5): bdev /dev/nvme1n1p5 errs: wr 0, rd 0, flush 0, corrupt 9, gen 0
Sep 21 13:55:23 zesko kernel: BTRFS error (device nvme1n1p5): bdev /dev/nvme1n1p5 errs: wr 0, rd 0, flush 0, corrupt 10, gen 0
-
I switched btrfs to ext4 on the same partition (deleting the partition then creating new partition with EXT4 on the same location of SSD).
-
I checked
badblockagain, the result showed no bad block. -
I checked
e2fsckthat supports extX only, not btrfs:
❯ sudo e2fsck -c /dev/nvme1n1p5
e2fsck 1.46.4 (18-Aug-2021)
Checking for bad blocks (read-only test): done
Test: Updating bad block inode.
Pass 1: Checking inodes, blocks, and sizes
Pass 2: Checking directory structure
Pass 3: Checking directory connectivity
Pass 4: Checking reference counts
Pass 5: Checking group summary information
Test: ***** FILE SYSTEM WAS MODIFIED *****
Test: 11/12804096 files (0.0% non-contiguous), 1081283/51200000 blocks
- I tested many copies on EXT4 again:
/run/media/zesko/Test ❯ cp test1.zip test2.zip # OK
/run/media/zesko/Test ❯ cp test2.zip test3.zip # OK
/run/media/zesko/Test ❯ cp test3.zip test4.zip # OK
/run/media/zesko/Test ❯ cp test4.zip test5.zip # OK
/run/media/zesko/Test ❯ cp test5.zip test6.zip # OK
/run/media/zesko/Test ❯ cp test6.zip test7.zip # OK
/run/media/zesko/Test ❯ cp test7.zip test8.zip # OK
/run/media/zesko/Test ❯ cp test9.zip test10.zip # OK
/run/media/zesko/Test ❯ cp test10.zip test11.zip # OK
/run/media/zesko/Test ❯ cp test11.zip test12.zip # OK
/run/media/zesko/Test ❯ cp test12.zip test13.zip # OK
/run/media/zesko/Test ❯ cp test13.zip test14.zip # OK
All copies have no issue on ext4. I checked the latest zip test13.zip that has few bad files (bad CRC) after 13 times copies.
I can confirm that BTRFS has the writing bug with SSD without RAID. EXT4 has no issue.
I stop the return of my new SSD because it is Okay.
So to reiterate, these aren’t even newly compressed files, just simple copies of the original .zip file:
Ext4:
Even after 13 copies, every single file has the same checksum and passes their internal integrity test?
Btrfs:
Just after only few copies of the same file, there’s an I/O error and the third .zip copy is corrupted?
When you made 13 copies of the same .zip file under Ext4, and they all passed, did you also verify they all had the same SHA1 checksum?
sha1sum *.zip
@linux-aarhus is this an example of Btrfs “barfing”?
@Zesko do you have the time to run a full memtest pass and mprime, to rule out the CPU and RAM?
1 Like
Maybe, the compression of btrfs is what produces the fault ?
Compression of already compressed files seems to be tricky.
I can’t speak for Btrfs, but with ZFS the default inline compression of LZ4 simply “skips” attempting to compress a record if it determines ahead of time that the data will not be worth compressing.
I assume Btrfs’ inline compression does the same thing? ![]()
EDIT: Besides that, it’s no excuse for a write to be corrupted.
The bugs don’t ask if there is an excuse available ![]()
No, every zip file has the different checksum. The latest zip has more bad CRC than the first zip. But BTRFS too.
Not always third .zip is corrupted. When I tried to overwrite it (copy test2.zip to test3.tip) again, then no error. But sometimes the next random number of copy will be corrupted.
I checked my both SSDs, both have the same issue.
Whoa, whoa, whoa! Time out! Something’s way off here.
![]()
Definitely run a few memtest passes completely, and run mprime overnight (or as long as you can spare.)
This doesn’t look like a filesystem issue anymore.
It must but one of the following, or a combination:
- Drive (less likely since you said it happens on different drives)
- RAM ← most likely
- CPU ← not as likely, but must rule it out
But when you copy the checksum should stay allways the same ! ![]()
I see, but I thought every zip file that has the different timestamp.
You’re doing a file copy. Timestamps are saved as metadata in the filesystem; not on the file itself.
If you copy a .zip file a MILLION times and have a MILLION copies, they should all have the same sha1 checksum.
Weren’t you simply using the cp command to make 13 copies of the same .zip file under Ext4?
test1.zip 15 GB Chechsum: MD5: b729c897a8259383d0dc979c8d534e55
test2.zip 15 GB Chechsum: MD5: b729c897a8259383d0dc979c8d534e55
test3.zip 15 GB Chechsum: MD5: 78df6e8e3eba0de4ee41aeeadfd1a905
on EXT4, the size of zip is big.
I seriously think it’s a RAM or CPU issue (and still haven’t entirely ruled out the drives, but those are less likely to be failing at the same time while reporting no obvious errors).
2 Likes
A 15G zip file is an edge case -and I don’t think this is descriptive for the filesystem as such.
My experience is a couple of years back an in my case it was my entire projects partion which went haywire.
Such a projects structure is literally tens of thousands of files when you count in the git structure with tiny bits of fragments.
I don’t know what caused it - luckily it was only a filesystem test - so I had 99% stored on a removable device. I lost tiny pieces but my trust in said filesystem vanished and I have never touched it since.
Even f2fs has done something similiar - which is why I now use ext4 only.
1 Like
It would be dangerous for full disk encryption with LUKS when a data is corrupted, then it could not be decrypted anymore?
My both SSDs are not encrypted as they always stay home, unlike laptop.
That is a possibility.
This looks quite bad and you should check your ram and other system components as advised.
As it stands now, you cannot be certain of the data integrety of any data written by your machine.
Files installed via packages can be checked with paccheck from pacutils package:
$ sudo paccheck --sha256sum --quiet
For any other (important) file you can only try to check against a backup and inspect all changes manually.
Not only is it more difficult to do data recovery from an encrypted block device, as it is, but if there’s any corruption to the LUKS header (and its backup) due to faulty CPU, RAM, SSD, you essentially “securely wiped” your data permanently.
Once your system demonstrates it consistently writes the incorrect bits into a new file (or copy), it’s practically compromised. You cannot trust anything else.
You can no longer trust…
- updates
- package installations
- creating new files
- saving files
- copying files
- downloads
- transferring multimedia to and from the computer
…and so on.
In the end, your only means to protect yourself against losing data permanently is not redundancy/RAID, not bitrot protection against corruption, and not even a simple backup (in which it can fail in cold storage), but rather multiple backups of different types, and frequently using them and checking them.
But that’s off topic! ![]()
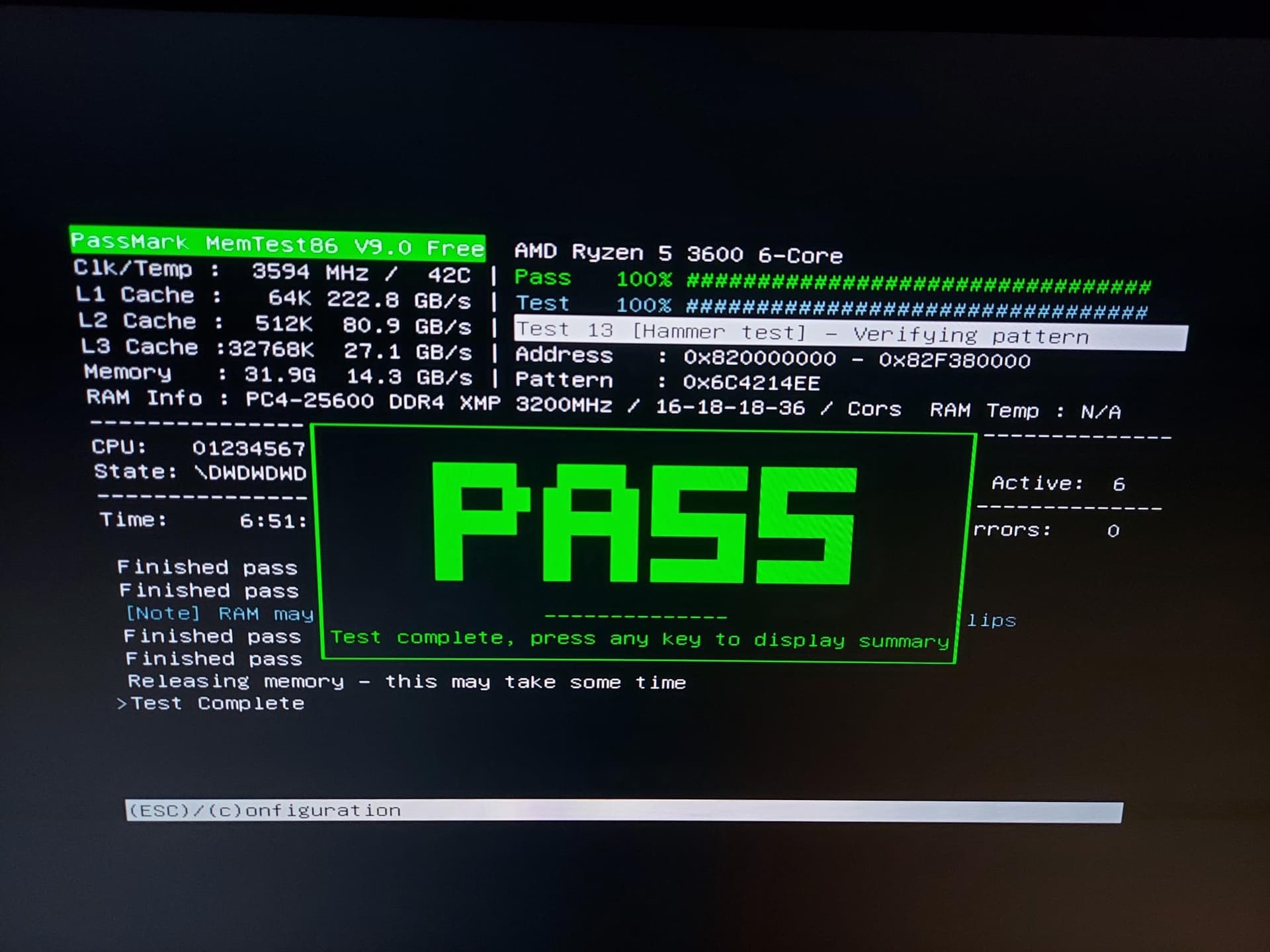
memtest86-efi has completely tested after 7 hours. Everything is OK. 
But it showed [Note] RAM may be vulnerable to high frequency row hammer bit flips.
I found another problem. Not only copy errors, but also reading or CPU calculation errors too?
The same file test1.zip has many different checksum. 
 I did not change it.
I did not change it.
❯ sha1sum test1.zip
e9bb2bfc90ad058aa73154cce4814fd744cc11f8 test1.zip # Failed
❯ sha1sum test1.zip
ea1127716ab44a6b74507ec7c503409ae5e84f21 test1.zip # Failed
❯ sha1sum test1.zip
bdb8b9098a3b0fc7055f20af586457156023be2d test1.zip # Failed
❯ sha1sum test1.zip
0d7f28ed306c395baa0ec9436a356672843e9021 test1.zip # Failed
on my old SSD.
❯ sha1sum test1.zip
b35cd8b5df411a5b20ac456f67b95f089502919f test1.zip # OK
❯ sha1sum test1.zip
b35cd8b5df411a5b20ac456f67b95f089502919f test1.zip # OK
❯ sha1sum test1.zip
f48ea7c128e8f7f892636f8c05623a243ec09c01 test1.zip # Failed
❯ sha1sum test1.zip
3f2b211343854f8d2faf70800e76a86ff75106a9 test1.zip # Failed
❯ sha1sum test1.zip
f4ec8624a5ae5f61bd3b7e95b898dc841436fd6e test1.zip # Failed
on my new SSD.
Both SSDs are affected on the same device 1.
I checked the same file 15GB in my USB stick 64GB (EXT4) on my device 1, it shows different checksums too.
But I checked this USB stick on my other device 2, then no issue → The same file shows always the same checksum.
I checket the zip on Windows 10 on the same device 1, but only data transfer or copy has the problem too, but many copies are correct, few are incorrect, but checksum is always the same for individual zip, but on Linux it shows random different checksums.
The device 1 is currently running with mprime. I see many were passed.
I checked the zip file with the help of Manjaro Live USB on the device 1, the same issue.
I stop mprime now. I try to set the mainboard BIOS setting, for example AMD-V is switched off. I remove 3 of 4 RAMs, then I see if it works.
1 Like