Background:
My previous Raid 1 array (drive T1 and T2) degraded due to 1 single disk failure (T2).
To prevent data loss, I backup the content of the Raid 1 array onto another HDD, before I deleted the Raid 1 array and rebuilt.
So my steps were:
-
unmount Raid 1 array
umount /dev/Raid1 -
stop Raid 1 array
mdadm --stop /dev/md/Raid1 -
remove Raid 1 array - this step reported “no device found”.
mdadm --remove /dev/md/Raid1 -
remove superblocks - and I guess this step deleted all array information?
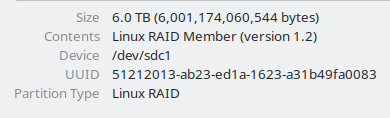
mdadm --zero-superblock /dev/sdc1 /dev/sdd1 -
verify Raid device removed - and yup, nothing found.
cat /proc/mdstat
I then proceeded to remove the faulty drive (T2), and replaced with a working drive (S1).
At this point, I also presumed that although raid info has been removed in step (4), the data should still present in disk T1, and thus, I went ahead to format the disk T1 using Gnome Disk, and I also run some partitioning using KDE partition manager. All these “plays” should sufficiently delete the data.
Finally, I setup new Raid 1 array again.
-
I used
fdiskto prepare the disks, and chose 43 (ie. Linux raid partition type) for both disks. -
Setup raid array
sudo mdadm --create /dev/md/NAS1 --level=mirror --raid-devices=2 /dev/sdc1 /dev/sdd1 -
The
cat /proc/mdstatshowed that raid1 is active, and the array was syncing. -
Again,
sudo mdadm --detail /dev/md/NAS1showed thatState: clean, resyncing
So, it seemed like the process was successful, and I should have the new Raid 1 array ready to use.
Then, what’s the problem?
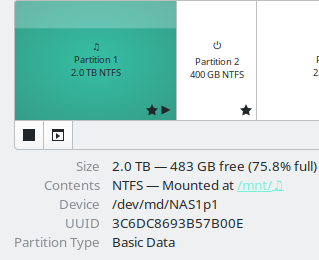
When I opened Gnome Disk, the new Raid 1 array showed the old partition layout from the old array.
After running Step (4) to zero the superblock, and after multiple formating of disk T1, I have not expected the partition layout to preserve, nor any data inside the old raid.
Yet, it was there.
I compared the file numbers, file size, etc, with my backup copy, and none is missing.
Eventually, I proceeded to delete the partitions of old layout, and re-partitioned the new Raid 1 array.
So now I have questions:
a. How did the old partition layout and the old data survived mdadm --zero-superblock and Format disk in Gnome disk, as well as KDE Partition Manager? Did I miss some step in order to wipe clean both Raid metadata and partition data?
b. My current raid status is:
/dev/md/NAS1:
Version : 1.2
Creation Time : Wed Nov 1 00:13:53 2023
Raid Level : raid1
Array Size : 5860389440 (5.46 TiB 6.00 TB)
Used Dev Size : 5860389440 (5.46 TiB 6.00 TB)
Raid Devices : 2
Total Devices : 2
Persistence : Superblock is persistentIntent Bitmap : Internal Update Time : Thu Nov 2 22:03:55 2023 State : clean Active Devices : 2Working Devices : 2
Failed Devices : 0
Spare Devices : 0Consistency Policy : bitmap
Name : Me:NAS1 (local to host Me) UUID : 51212013:ab23ed1a:1623a31b:49fa0083 Events : 6805 Number Major Minor RaidDevice State 0 8 33 0 active sync /dev/sdc1 1 8 49 1 active sync /dev/sdd1
Apparently the new Raid 1 is functioning.
But after the persistent old data issue, I’m running a bit paranoia - is there any “soft” way to verify the new data is present on both HDDs, ie. without removing the cable/HDD?
Appreciate your input!