I’ve installed this SSD in my ASUS TUF F15 F506HM gaming laptop where I was using this SSD (single partition, BTRFS) to store my data.
I’ve used the laptop last month, when it was fine. I went for a vacation and only opened the laptop yesterday, following which, I’ve started seeing massive system slowdowns whenever I open any file from this drive.
I did the usual maintenance on BTRFS, I ran balance and then now it stopped booting altogether and my SSD is only being mounted in read only mode.
This is when I went into the product page to see the reviews, and many people are claiming that these SSDs are stopping to work after 1-8 months. One of the reviews even said that the sticker says 2 TB of storage capacity but Windows is only showing 250 GB of space on it.
Need help in trying to find out what exactly went wrong. Although I do have backups, I’d like to investigate this further.
The SSD that came with the laptop is the OS SSD (I installed Manjaro) and this second SSD from Crucial is my home partition.
Although the category is support, I’m only seeking the direction in which I should explore. Linux troubleshooting has been fun for me over the past year after all.
Do the basics, remove and remount the SSD on the motherboard, verify it is correctly seated. If it is read only that probably means there are file system errors.
About the ‘reviews’ that seems weird to me as Crucial is to me one of the best manufacturer. You have to be careful who you’re buying from too, I only buy product on Amazon when it is sold and shipped BY AMAZON, if you buy to shady distributors the issue can be that you’re shipped refurbished or bad products (also known as a scam).
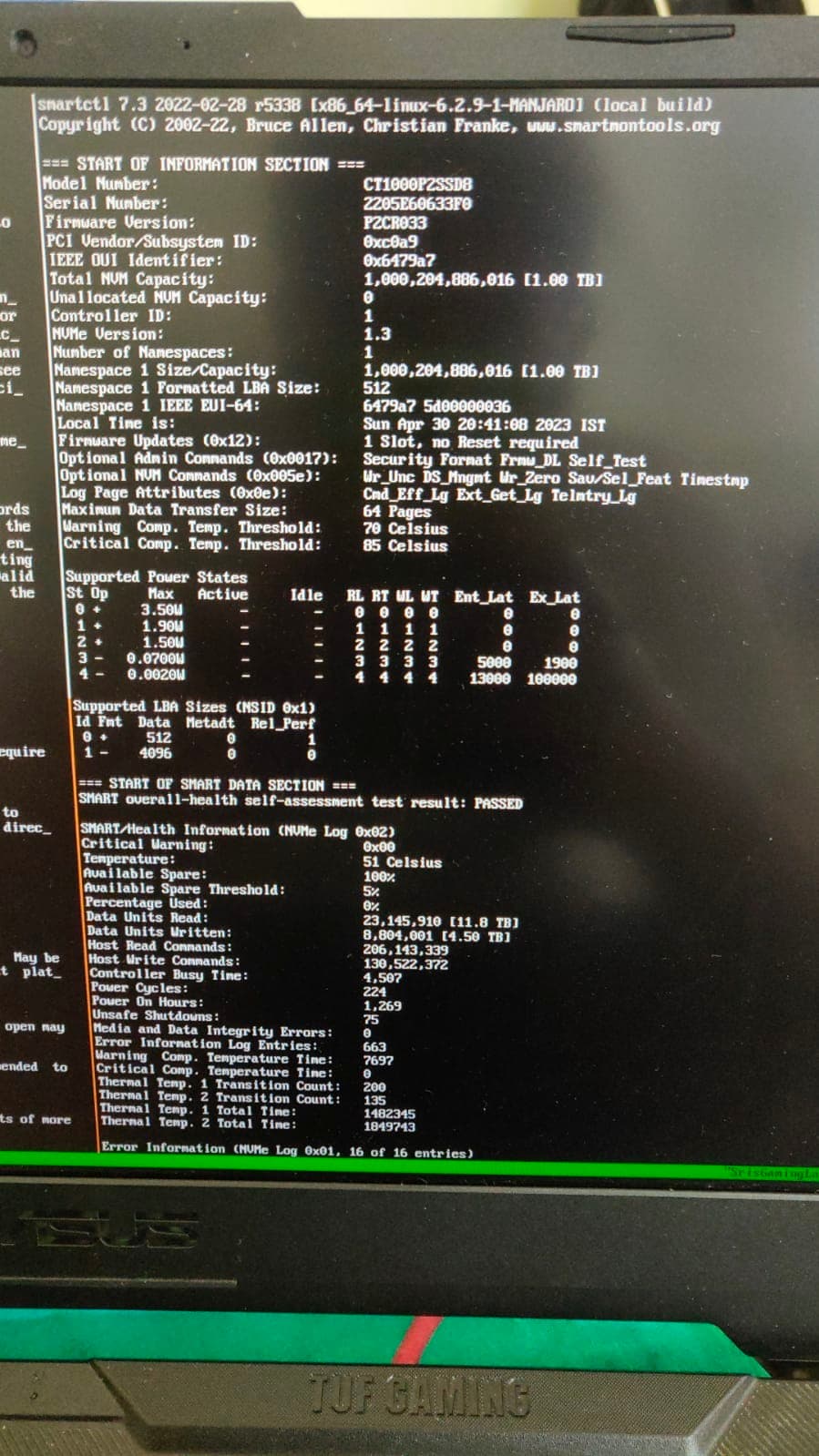
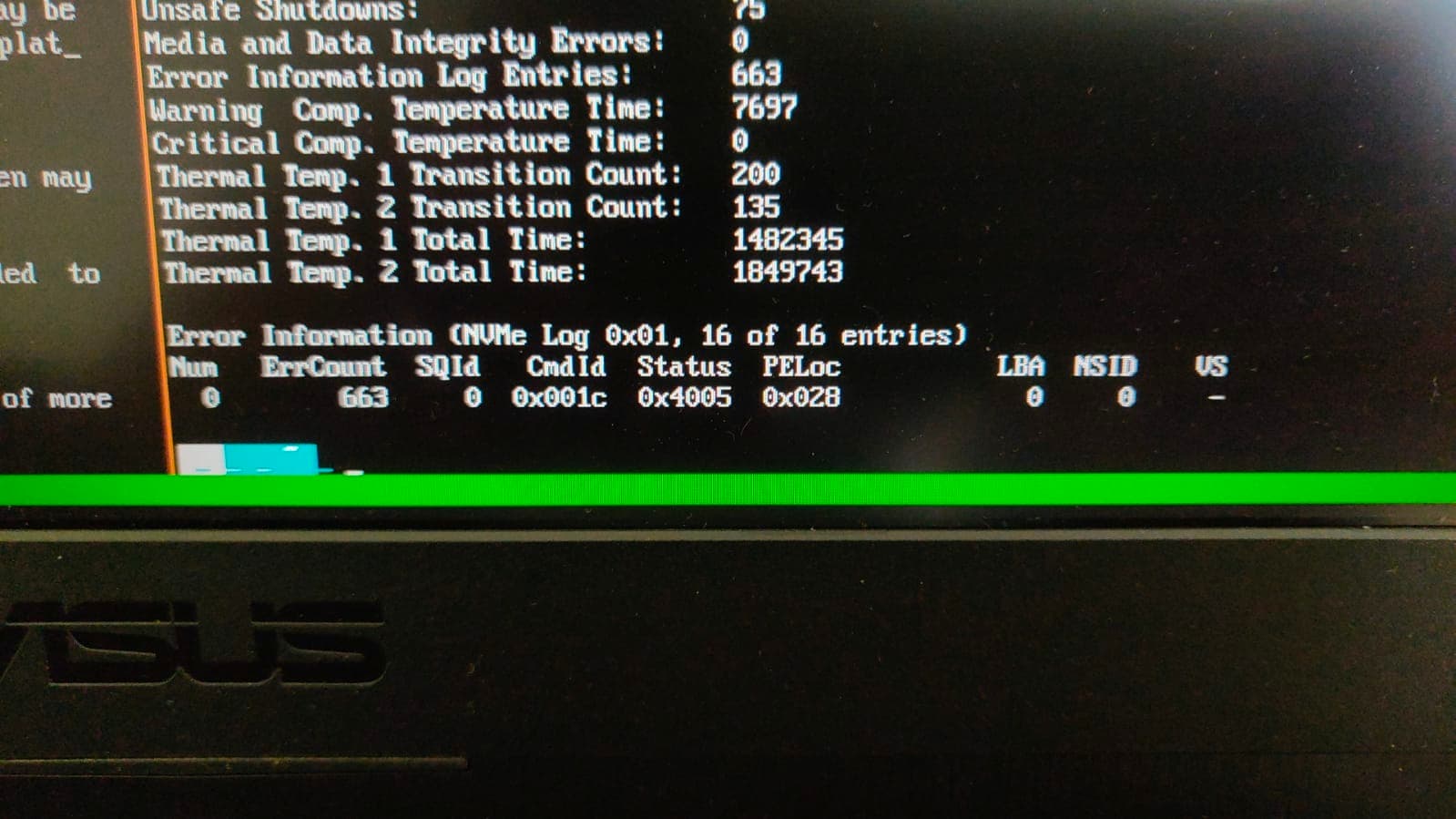
Check the SMART of the drive first and see what it reports.
SMART never worked for me, right from the start. The moment I inserted the SSD, I started SMART failure in boot time, and after reading through Crucial’s website, I learned that SMART doesn’t exist for NVME SSDs, so I disabled it in BIOS.
However, I also couldn’t find any SMART info (even with smartmontools, not just KDE Partition Manager) for the built-in SSD as well. Let me try removing and re-inserting it.
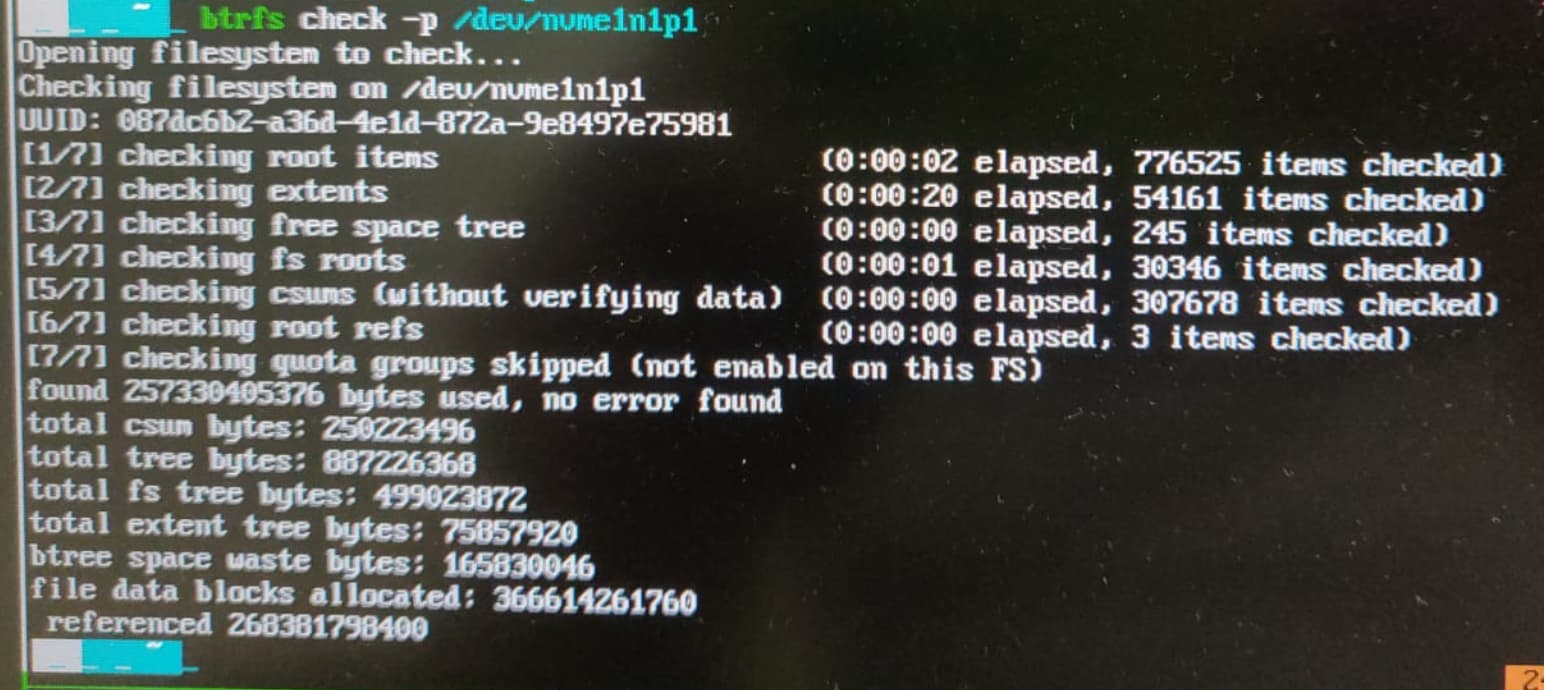
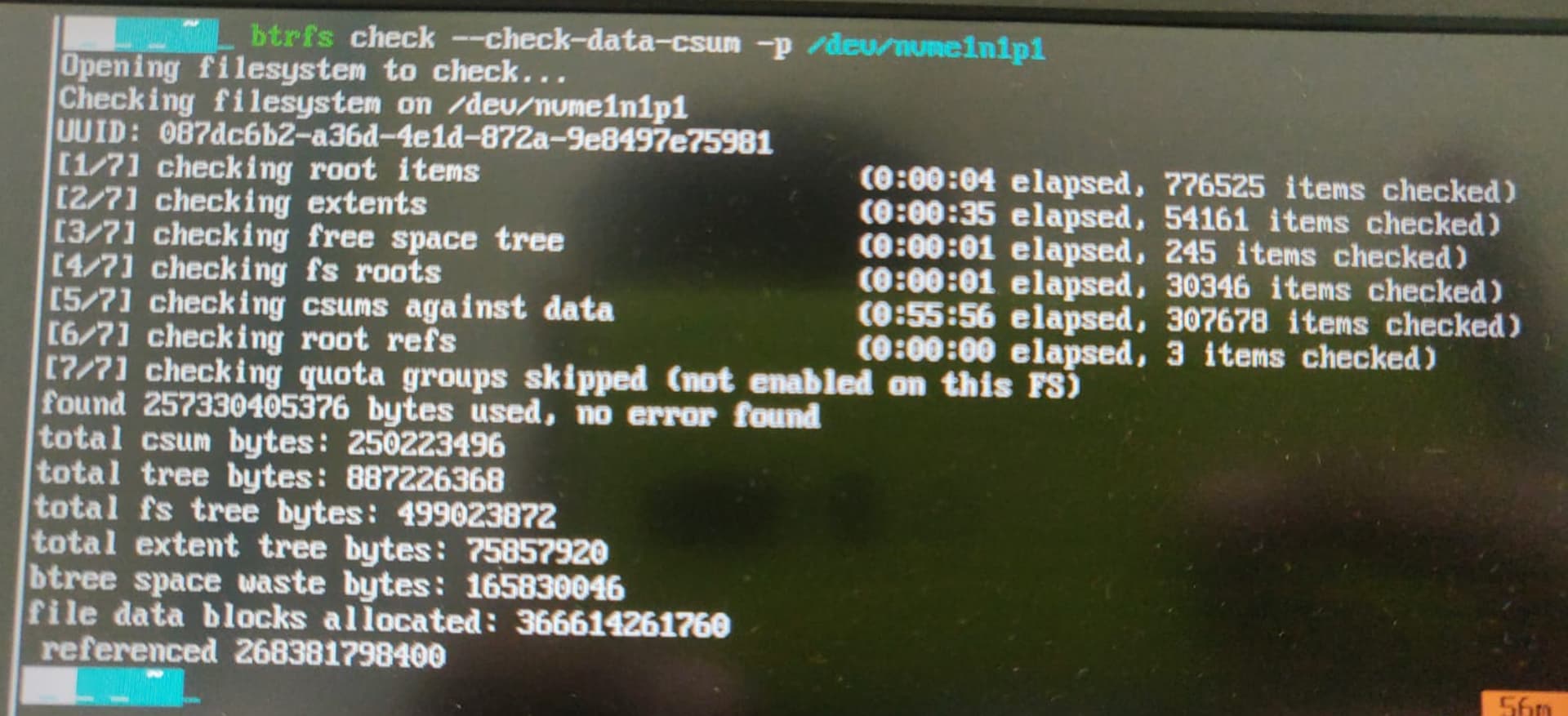
Sorry for the images, I don’t know how to copy and paste from TMUX when using recovery mode. Do you think I should run btrfs-check?
I do have my backups in a separate external hard disk and on cloud, but don’t want to risk the SSD if it is actually good. The wiki page is showing a lot of warnings. I think I’ll just run without the --repair switch and see what happens.
Yes do as the manual says, don’t use --repair and force --readonly
If you can work from live USB environment you can connect to forum and post proper logs, as images of text, yeah, aren’t good for helping troubleshooting efficiently.
Thanks a lot! My system is now bootable after running btrfs check. Seems like some flag was set during some error before that was now cleared. However, when reading large files, SSD is still jumping temperatures to 78C which is causing SMART to report failure, since warning temperature rating is 70C for me. Room temperature currently is 38C here and CPU temp is 64C on IDLE for 10 minutes.
However, something happened with my swapfile though. It can no longer find my swapfile. So I had to remove the resume parameter from the boot logs.
I want to experiment with dynamic swap, so will open a separate thread for that soon.
Anything relevant to your issue from the command output? btrfs check should not have done ANYTHING at all, it should have just checked its things, and report, so something is weird here.
If you’re overheating components, then this in itself is an issue you need to check and fix, maybe clean the computer and maybe force fan speed to go higher.
It took a long time, but this also said there are no issues. I think overheating might be the issue now.
Since it’s been an year anyways, I’ll clean it up and I think I’ll also re-apply the thermal paste. CPU temperature is also going quite high. It’s touching 90C now.
Maybe reseating fixed it actually. Sometimes it can work for a while even if it is not seated correctly and suddenly it stops working or generates errors.
But yeah, you need to clear this overheating issue I think.