About a month ago, beginning of march, I noticed I had a lot of available upgrades (some 300 packages). Maybe foolishly I just pressed “Upgrade all” or whatever it said…and after that my system doesn’t boot.
Unfortunately I’m not competent enough to sort it out myself, and I don’t even know where to start.
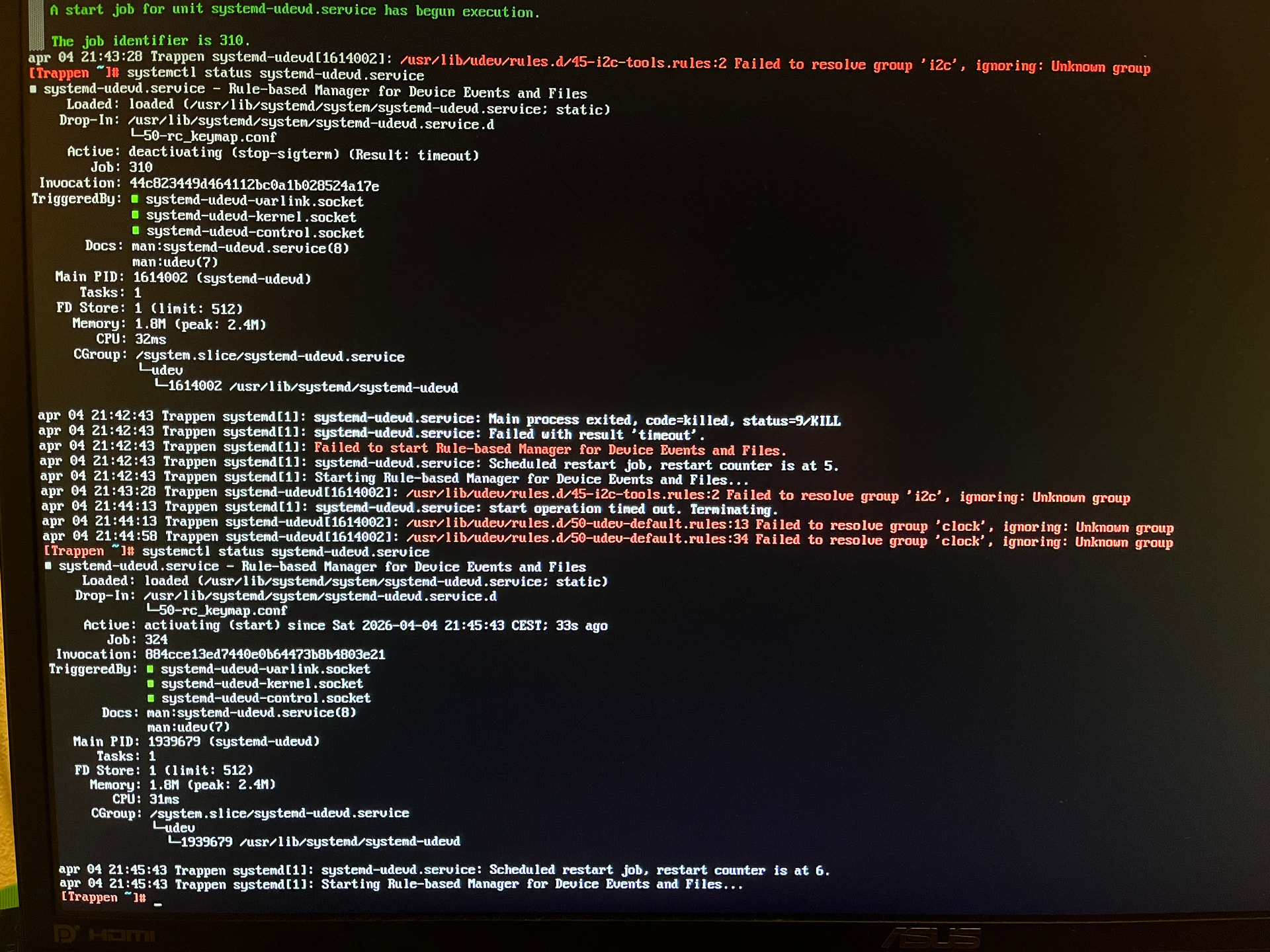
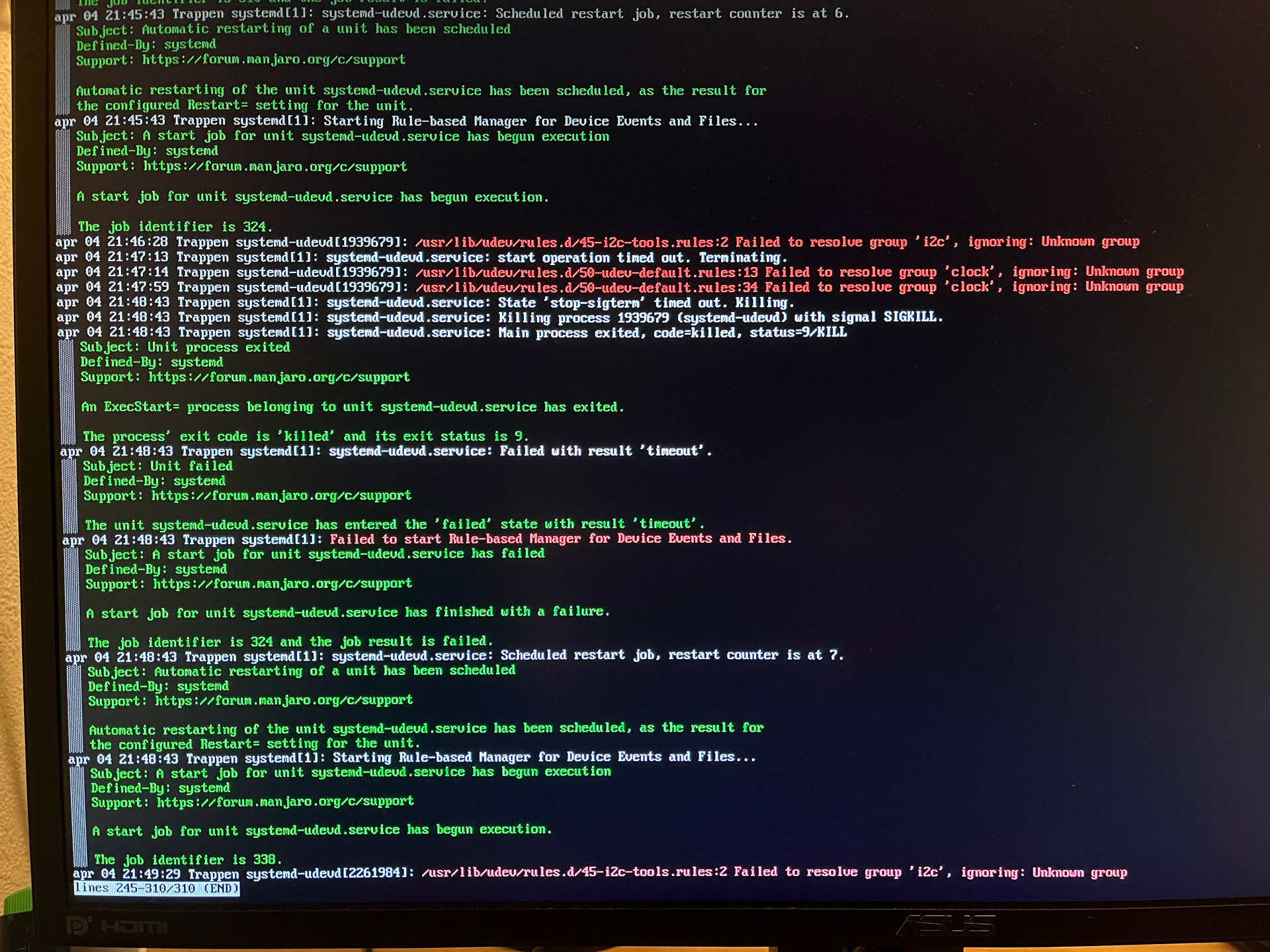
When just letting my system try to boot, I eventually come to a terminal screen telling me I’m in “Emergency mode”, and asking me to enter the root password and hinting on running “journalctl -xb”.
Those about 1500 lines of outputs doesn’t really help me.
What shall I look for?
I can get my system up and running by selecting a snapshot from 2026-03-07 (which might be just before my upgrade attempt).
Can/shall I start from this snapshot and fix from there, or is it better to stay on the failed default boot option and fix from there?
Any help appreciated.
/BA