Yet another edit, previous versions below:
I have found the issue, but I don’t know how to solve it.
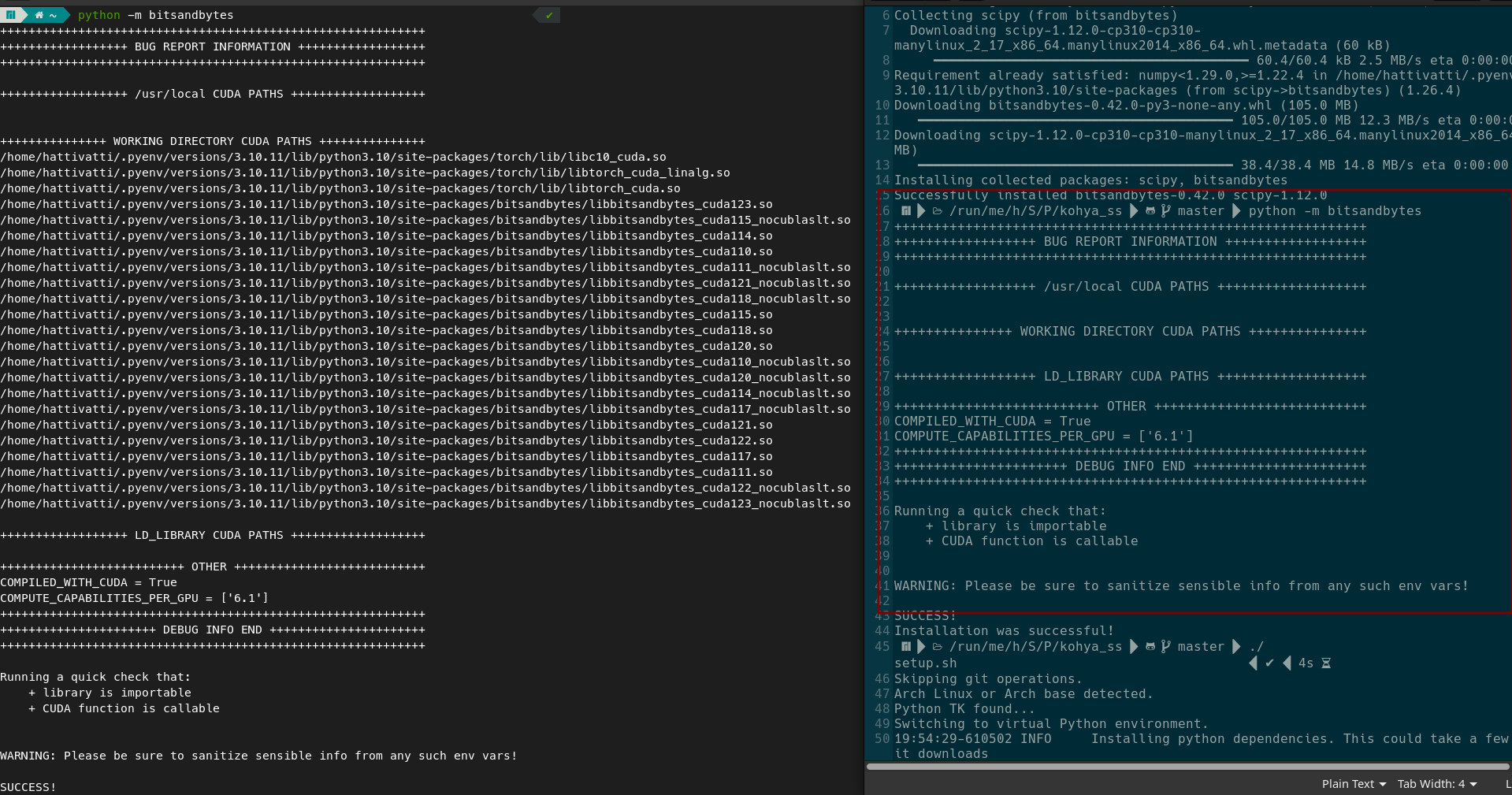
On the left, you’ll see I ran “python -m bitsandbites” and it finds my cuda stuff fine. On the right is the terminal output from when I ran terminal inside of my Kohya folder.
Kohya requires running with pyenv to shim the python version. I noticed when I ran the setup.sh file via right click → run as program, it would fail to detect my shim. But when I run it via terminal inside the folder (the right image), it fails to detect my libraries, but it does successfully shim my python.
I don’t know how to fix this, though. If I run the setup without the shim, it seems to run, but it detects the wrong python version. But if I run it with the shim, it doesn’t seem to find my cuda libraries.
My kohya is on a different drive than my operating system. I’ve had it running successfully on this very drive before, so I don’t know why that would be an issue. Just wanted to put it out there.
Heavy Edit (Original Below Line Divider)
I’ve continued to tinker with it, and I indeed think that Kohya is having a hard time pathing to the Cuda stuff. In the setup.sh file (available on the linked github below), there does seem to be lots of references to the LD_LIBRARY_PATH. I also tried installing an older version of Kohya and the outputs were mere helpful regarding the error. It did seem to suggest it was having a hard time locating some Cuda libs or something. Again, a bit over my head. I have reinstalled the current version, but this time, I did it all within one terminal window, therefore it will all be streamlined in one location. I don’t understand code or python at all. I’m not sure what it takes to update a path for the variable, let alone what path I’m even looking for?
/run/me/h/S/P/kohya_ss master python -V ✔
Python 3.10.11
/run/me/h/S/P/kohya_ss master pip install bitsandbytes ✔
Collecting bitsandbytes
Downloading bitsandbytes-0.42.0-py3-none-any.whl.metadata (9.9 kB)
Collecting scipy (from bitsandbytes)
Downloading scipy-1.12.0-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl.metadata (60 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 60.4/60.4 kB 2.5 MB/s eta 0:00:00
Requirement already satisfied: numpy<1.29.0,>=1.22.4 in /home/hattivatti/.pyenv/versions/3.10.11/lib/python3.10/site-packages (from scipy->bitsandbytes) (1.26.4)
Downloading bitsandbytes-0.42.0-py3-none-any.whl (105.0 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 105.0/105.0 MB 12.3 MB/s eta 0:00:00
Downloading scipy-1.12.0-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (38.4 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 38.4/38.4 MB 14.8 MB/s eta 0:00:00
Installing collected packages: scipy, bitsandbytes
Successfully installed bitsandbytes-0.42.0 scipy-1.12.0
/run/me/h/S/P/kohya_ss master python -m bitsandbytes
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
++++++++++++++++++ BUG REPORT INFORMATION ++++++++++++++++++
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
++++++++++++++++++ /usr/local CUDA PATHS +++++++++++++++++++
+++++++++++++++ WORKING DIRECTORY CUDA PATHS +++++++++++++++
++++++++++++++++++ LD_LIBRARY CUDA PATHS +++++++++++++++++++
++++++++++++++++++++++++++ OTHER +++++++++++++++++++++++++++
COMPILED_WITH_CUDA = True
COMPUTE_CAPABILITIES_PER_GPU = ['6.1']
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
++++++++++++++++++++++ DEBUG INFO END ++++++++++++++++++++++
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
Running a quick check that:
+ library is importable
+ CUDA function is callable
WARNING: Please be sure to sanitize sensible info from any such env vars!
SUCCESS!
Installation was successful!
/run/me/h/S/P/kohya_ss master ./setup.sh ✔ 4s
Skipping git operations.
Arch Linux or Arch base detected.
Python TK found...
Switching to virtual Python environment.
19:54:29-610502 INFO Installing python dependencies. This could take a few minutes as it downloads
files.
19:54:29-614328 INFO If this operation ever runs too long, you can rerun this script in verbose mode
to check.
19:54:29-615335 INFO Version: v22.6.2
19:54:29-616238 INFO Python 3.10.11 on Linux
19:54:29-617529 INFO Installing modules from requirements_linux.txt...
19:54:29-618532 INFO Installing package: torch==2.0.1+cu118 torchvision==0.15.2+cu118
--extra-index-url https://download.pytorch.org/whl/cu118
19:55:39-781275 INFO Installing package: xformers==0.0.21 bitsandbytes==0.41.1
19:55:45-267134 INFO Installing package: tensorboard==2.14.1 tensorflow==2.14.0
19:56:08-282542 INFO Installing modules from requirements.txt...
19:56:08-283754 INFO Installing package: accelerate==0.25.0
19:56:10-763052 INFO Installing package: aiofiles==23.2.1
19:56:11-647159 INFO Installing package: altair==4.2.2
19:56:20-397948 INFO Installing package: dadaptation==3.1
19:56:21-509331 INFO Installing package: diffusers[torch]==0.25.0
19:56:24-887533 INFO Installing package: easygui==0.98.3
19:56:26-474757 INFO Installing package: einops==0.7.0
19:56:27-679318 INFO Installing package: fairscale==0.4.13
19:56:29-208834 INFO Installing package: ftfy==6.1.1
19:56:30-475121 INFO Installing package: gradio==3.50.2
19:56:45-511466 INFO Installing package: huggingface-hub==0.20.1
19:56:47-431944 INFO Installing package: invisible-watermark==0.2.0
19:56:50-397830 INFO Installing package: lion-pytorch==0.0.6
19:56:51-675122 INFO Installing package: lycoris_lora==2.0.2
19:56:58-550373 INFO Installing package: omegaconf==2.3.0
19:57:00-571637 INFO Installing package: onnx==1.14.1
19:57:04-262950 INFO Installing package: onnxruntime-gpu==1.16.0
19:57:09-067969 INFO Installing package: protobuf==3.20.3
19:57:11-232247 INFO Installing package: open-clip-torch==2.20.0
19:57:14-037836 INFO Installing package: opencv-python==4.7.0.68
19:57:17-083098 INFO Installing package: prodigyopt==1.0
19:57:19-077856 INFO Installing package: pytorch-lightning==1.9.0
19:57:24-148369 INFO Installing package: rich==13.7.0
19:57:26-571948 INFO Installing package: safetensors==0.4.2
19:57:28-777800 INFO Installing package: timm==0.6.12
19:57:31-321192 INFO Installing package: tk==0.1.0
19:57:33-402054 INFO Installing package: toml==0.10.2
19:57:35-498712 INFO Installing package: transformers==4.36.2
19:57:42-844890 INFO Installing package: voluptuous==0.13.1
19:57:44-873888 INFO Installing package: wandb==0.15.11
19:57:50-285120 INFO Installing package: scipy==1.11.4
19:57:55-679614 INFO Installing package: -e .
19:58:00-715828 INFO Configuring accelerate...
19:58:00-717231 WARNING Could not automatically configure accelerate. Please manually configure
accelerate with the option in the menu or with: accelerate config.
Exiting Python virtual environment.
Setup finished! Run ./gui.sh to start.
Please note if you'd like to expose your public server you need to run ./gui.sh --share
/run/me/h/S/P/kohya_ss master ./gui.sh ✔ 3m 36s
Warning: LD_LIBRARY_PATH environment variable is not set.
Certain functionalities may not work correctly.
Please ensure that the required libraries are properly configured.
If you use WSL2 you may want to: export LD_LIBRARY_PATH=/usr/lib/wsl/lib/
20:00:30-508391 INFO Version: v22.6.2
20:00:30-512935 INFO nVidia toolkit detected
20:00:31-583852 INFO Torch 2.0.1+cu118
20:00:31-593342 INFO Torch backend: nVidia CUDA 11.8 cuDNN 8700
20:00:31-624325 INFO Torch detected GPU: NVIDIA GeForce GTX 1080 Ti VRAM 11169 Arch (6, 1) Cores 28
20:00:31-626174 INFO Verifying modules installation status from
/run/media/hattivatti/StableDiffusionS/Programs/kohya_ss/requirements_linux.txt
...
20:00:31-629306 INFO Verifying modules installation status from requirements.txt...
20:00:34-926964 INFO headless: False
20:00:34-930507 INFO Load CSS...
Running on local URL: http://127.0.0.1:7860
To create a public link, set `share=True` in `launch()`.
20:01:08-347220 INFO Loading config...
20:01:09-312804 INFO Loading config...
20:01:32-576599 INFO Loading config...
20:01:33-550554 INFO Start training Dreambooth...
20:01:33-552697 INFO Valid image folder names found in:
/run/media/hattivatti/1TBOverflow/ModelOutput/img
20:01:33-554702 INFO Valid image folder names found in:
/run/media/hattivatti/1TBOverflow/ModelOutput/reg
20:01:33-556590 INFO Folder 2_M00seArt art style : steps 178
20:01:33-558175 INFO Regularisation images are used... Will double the number of steps required...
20:01:33-559971 INFO max_train_steps (178 / 2 / 1 * 20 * 2) = 3560
20:01:33-561880 INFO stop_text_encoder_training = 0
20:01:33-563325 INFO lr_warmup_steps = 178
20:01:33-564879 INFO Saving training config to
/run/media/hattivatti/1TBOverflow/ModelOutput/model/M00seArt_20240302-200133.js
on...
20:01:33-567100 INFO accelerate launch --num_cpu_threads_per_process=2 "./train_db.py"
--bucket_no_upscale --bucket_reso_steps=64 --enable_bucket
--min_bucket_reso=384 --max_bucket_reso=1024 --learning_rate="0.0001"
--learning_rate_te="1e-05"
--logging_dir="/run/media/hattivatti/1TBOverflow/ModelOutput/log"
--lr_scheduler="constant_with_warmup" --lr_scheduler_num_cycles="20"
--lr_warmup_steps="178" --max_data_loader_n_workers="0" --resolution="512,512"
--max_train_steps="3560" --mixed_precision="fp16" --optimizer_type="AdamW8bit"
--output_dir="/run/media/hattivatti/1TBOverflow/ModelOutput/model"
--output_name="M00seArt"
--pretrained_model_name_or_path="/run/media/hattivatti/StableDiffusionS/Program
s/stable-diffusion-webui/models/Stable-diffusion/artUniverse_v80.safetensors"
--random_crop
--reg_data_dir="/run/media/hattivatti/1TBOverflow/ModelOutput/reg"
--save_every_n_epochs="1" --save_model_as=safetensors --save_precision="fp16"
--train_batch_size="2"
--train_data_dir="/run/media/hattivatti/1TBOverflow/ModelOutput/img" --xformers
The following values were not passed to `accelerate launch` and had defaults used instead:
`--num_processes` was set to a value of `1`
`--num_machines` was set to a value of `1`
`--mixed_precision` was set to a value of `'no'`
`--dynamo_backend` was set to a value of `'no'`
To avoid this warning pass in values for each of the problematic parameters or run `accelerate config`.
2024-03-02 20:01:37.939688: E tensorflow/compiler/xla/stream_executor/cuda/cuda_dnn.cc:9342] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered
2024-03-02 20:01:37.939721: E tensorflow/compiler/xla/stream_executor/cuda/cuda_fft.cc:609] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered
2024-03-02 20:01:37.939743: E tensorflow/compiler/xla/stream_executor/cuda/cuda_blas.cc:1518] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
2024-03-02 20:01:37.945133: I tensorflow/core/platform/cpu_feature_guard.cc:182] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations.
To enable the following instructions: AVX2 FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.
2024-03-02 20:01:38.813610: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT
2024-03-02 20:01:39 INFO prepare tokenizer train_util.py:3959
2024-03-02 20:01:40 INFO prepare images. train_util.py:1469
INFO found directory train_util.py:1432
/run/media/hattivatti/1TBOverflow/ModelOutput/img/2_M00s
eArt art style contains 89 image files
WARNING No caption file found for 89 images. Training will train_util.py:1459
continue without captions for these images. If class
token exists, it will be used. /
89枚の画像にキャプションファイルが見つかりませんでした。
これらの画像についてはキャプションなしで学習を続行します
。class tokenが存在する場合はそれを使います。
WARNING /run/media/hattivatti/1TBOverflow/ModelOutput/img/2_M00s train_util.py:1466
eArt art style/1.png
WARNING /run/media/hattivatti/1TBOverflow/ModelOutput/img/2_M00s train_util.py:1466
eArt art style/10.png
WARNING /run/media/hattivatti/1TBOverflow/ModelOutput/img/2_M00s train_util.py:1466
eArt art style/11.png
WARNING /run/media/hattivatti/1TBOverflow/ModelOutput/img/2_M00s train_util.py:1466
eArt art style/12.png
WARNING /run/media/hattivatti/1TBOverflow/ModelOutput/img/2_M00s train_util.py:1466
eArt art style/13.png
WARNING /run/media/hattivatti/1TBOverflow/ModelOutput/img/2_M00s train_util.py:1464
eArt art style/14.png... and 84 more
INFO found directory train_util.py:1432
/run/media/hattivatti/1TBOverflow/ModelOutput/reg/1_art
style contains 254 image files
WARNING No caption file found for 254 images. Training will train_util.py:1459
continue without captions for these images. If class
token exists, it will be used. /
254枚の画像にキャプションファイルが見つかりませんでした
。これらの画像についてはキャプションなしで学習を続行しま
す。class tokenが存在する場合はそれを使います。
WARNING /run/media/hattivatti/1TBOverflow/ModelOutput/reg/1_art train_util.py:1466
style/00000-1214595497.png
WARNING /run/media/hattivatti/1TBOverflow/ModelOutput/reg/1_art train_util.py:1466
style/00001-2130368021.png
WARNING /run/media/hattivatti/1TBOverflow/ModelOutput/reg/1_art train_util.py:1466
style/00002-1697800000.png
WARNING /run/media/hattivatti/1TBOverflow/ModelOutput/reg/1_art train_util.py:1466
style/00008-3720950371.png
WARNING /run/media/hattivatti/1TBOverflow/ModelOutput/reg/1_art train_util.py:1466
style/00010-3011843286.png
WARNING /run/media/hattivatti/1TBOverflow/ModelOutput/reg/1_art train_util.py:1464
style/00011-3011843287.png... and 249 more
INFO 178 train images with repeating. train_util.py:1508
INFO 254 reg images. train_util.py:1511
WARNING some of reg images are not used / train_util.py:1513
正則化画像の数が多いので、一部使用されない正則化画像があ
ります
INFO [Dataset 0] config_util.py:544
batch_size: 2
resolution: (512, 512)
enable_bucket: True
network_multiplier: 1.0
min_bucket_reso: 384
max_bucket_reso: 1024
bucket_reso_steps: 64
bucket_no_upscale: True
[Subset 0 of Dataset 0]
image_dir:
"/run/media/hattivatti/1TBOverflow/ModelOutput/img/2_M00
seArt art style"
image_count: 89
num_repeats: 2
shuffle_caption: False
keep_tokens: 0
keep_tokens_separator:
caption_dropout_rate: 0.0
caption_dropout_every_n_epoches: 0
caption_tag_dropout_rate: 0.0
caption_prefix: None
caption_suffix: None
color_aug: False
flip_aug: False
face_crop_aug_range: None
random_crop: True
token_warmup_min: 1,
token_warmup_step: 0,
is_reg: False
class_tokens: M00seArt art style
caption_extension: .caption
[Subset 1 of Dataset 0]
image_dir:
"/run/media/hattivatti/1TBOverflow/ModelOutput/reg/1_art
style"
image_count: 254
num_repeats: 1
shuffle_caption: False
keep_tokens: 0
keep_tokens_separator:
caption_dropout_rate: 0.0
caption_dropout_every_n_epoches: 0
caption_tag_dropout_rate: 0.0
caption_prefix: None
caption_suffix: None
color_aug: False
flip_aug: False
face_crop_aug_range: None
random_crop: True
token_warmup_min: 1,
token_warmup_step: 0,
is_reg: True
class_tokens: art style
caption_extension: .caption
INFO [Dataset 0] config_util.py:550
INFO loading image sizes. train_util.py:794
100%|██████████████████████████████████████████████████████████████| 267/267 [00:00<00:00, 11221.01it/s]
INFO make buckets train_util.py:800
WARNING min_bucket_reso and max_bucket_reso are ignored if train_util.py:817
bucket_no_upscale is set, because bucket reso is defined
by image size automatically /
bucket_no_upscaleが指定された場合は、bucketの解像度は画像
サイズから自動計算されるため、min_bucket_resoとmax_bucket
_resoは無視されます
INFO number of images (including repeats) / train_util.py:846
各bucketの画像枚数(繰り返し回数を含む)
INFO bucket 0: resolution (512, 512), count: 356 train_util.py:851
INFO mean ar error (without repeats): 0.0 train_util.py:856
INFO prepare accelerator train_db.py:101
accelerator device: cuda
INFO loading model for process 0/1 train_util.py:4111
INFO load StableDiffusion checkpoint: train_util.py:4066
/run/media/hattivatti/StableDiffusionS/Programs/stable-d
iffusion-webui/models/Stable-diffusion/artUniverse_v80.s
afetensors
INFO UNet2DConditionModel: 64, 8, 768, False, False original_unet.py:1387
2024-03-02 20:01:45 INFO loading u-net: <All keys matched successfully> model_util.py:1009
INFO loading vae: <All keys matched successfully> model_util.py:1017
2024-03-02 20:01:47 INFO loading text encoder: <All keys matched successfully> model_util.py:1074
INFO Enable xformers for U-Net train_util.py:2529
prepare optimizer, data loader etc.
False
===================================BUG REPORT===================================
/run/media/hattivatti/StableDiffusionS/Programs/kohya_ss/venv/lib/python3.10/site-packages/bitsandbytes/cuda_setup/main.py:166: UserWarning: Welcome to bitsandbytes. For bug reports, please run
python -m bitsandbytes
warn(msg)
================================================================================
The following directories listed in your path were found to be non-existent: {PosixPath('/run/media/hattivatti/StableDiffusionS/Programs/kohya_ss/venv/lib/python3.10/site-packages/cv2/../../lib64')}
/run/media/hattivatti/StableDiffusionS/Programs/kohya_ss/venv/lib/python3.10/site-packages/bitsandbytes/cuda_setup/main.py:166: UserWarning: /run/media/hattivatti/StableDiffusionS/Programs/kohya_ss/venv/lib/python3.10/site-packages/cv2/../../lib64: did not contain ['libcudart.so', 'libcudart.so.11.0', 'libcudart.so.12.0'] as expected! Searching further paths...
warn(msg)
The following directories listed in your path were found to be non-existent: {PosixPath('local/hattivatti-tietokone'), PosixPath('@/tmp/.ICE-unix/1397,unix/hattivatti-tietokone')}
The following directories listed in your path were found to be non-existent: {PosixPath('-ccbin /opt/cuda/bin')}
The following directories listed in your path were found to be non-existent: {PosixPath('/sys/fs/cgroup/user.slice/user-1000.slice/user@1000.service/app.slice/app-dbus\\x2d'), PosixPath('1.2-org.gnome.Nautilus@3.service/memory.pressure'), PosixPath('1.2\\x2dorg.gnome.Nautilus.slice/dbus-')}
The following directories listed in your path were found to be non-existent: {PosixPath('/org/gnome/Terminal/screen/2f9c98bb_a83b_4358_9a26_13fb64b1264a')}
The following directories listed in your path were found to be non-existent: {PosixPath('//debuginfod.archlinux.org'), PosixPath('https')}
CUDA_SETUP: WARNING! libcudart.so not found in any environmental path. Searching in backup paths...
The following directories listed in your path were found to be non-existent: {PosixPath('/usr/local/cuda/lib64')}
DEBUG: Possible options found for libcudart.so: set()
CUDA SETUP: PyTorch settings found: CUDA_VERSION=118, Highest Compute Capability: 6.1.
CUDA SETUP: To manually override the PyTorch CUDA version please see:https://github.com/TimDettmers/bitsandbytes/blob/main/how_to_use_nonpytorch_cuda.md
/run/media/hattivatti/StableDiffusionS/Programs/kohya_ss/venv/lib/python3.10/site-packages/bitsandbytes/cuda_setup/main.py:166: UserWarning: WARNING: Compute capability < 7.5 detected! Only slow 8-bit matmul is supported for your GPU! If you run into issues with 8-bit matmul, you can try 4-bit quantization: https://huggingface.co/blog/4bit-transformers-bitsandbytes
warn(msg)
CUDA SETUP: Loading binary /run/media/hattivatti/StableDiffusionS/Programs/kohya_ss/venv/lib/python3.10/site-packages/bitsandbytes/libbitsandbytes_cuda118_nocublaslt.so...
libcusparse.so.11: cannot open shared object file: No such file or directory
CUDA SETUP: Problem: The main issue seems to be that the main CUDA runtime library was not detected.
CUDA SETUP: Solution 1: To solve the issue the libcudart.so location needs to be added to the LD_LIBRARY_PATH variable
CUDA SETUP: Solution 1a): Find the cuda runtime library via: find / -name libcudart.so 2>/dev/null
CUDA SETUP: Solution 1b): Once the library is found add it to the LD_LIBRARY_PATH: export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:FOUND_PATH_FROM_1a
CUDA SETUP: Solution 1c): For a permanent solution add the export from 1b into your .bashrc file, located at ~/.bashrc
CUDA SETUP: Solution 2: If no library was found in step 1a) you need to install CUDA.
CUDA SETUP: Solution 2a): Download CUDA install script: wget https://github.com/TimDettmers/bitsandbytes/blob/main/cuda_install.sh
CUDA SETUP: Solution 2b): Install desired CUDA version to desired location. The syntax is bash cuda_install.sh CUDA_VERSION PATH_TO_INSTALL_INTO.
CUDA SETUP: Solution 2b): For example, "bash cuda_install.sh 113 ~/local/" will download CUDA 11.3 and install into the folder ~/local
Traceback (most recent call last):
File "/run/media/hattivatti/StableDiffusionS/Programs/kohya_ss/./train_db.py", line 504, in <module>
train(args)
File "/run/media/hattivatti/StableDiffusionS/Programs/kohya_ss/./train_db.py", line 180, in train
_, _, optimizer = train_util.get_optimizer(args, trainable_params)
File "/run/media/hattivatti/StableDiffusionS/Programs/kohya_ss/library/train_util.py", line 3616, in get_optimizer
import bitsandbytes as bnb
File "/run/media/hattivatti/StableDiffusionS/Programs/kohya_ss/venv/lib/python3.10/site-packages/bitsandbytes/__init__.py", line 6, in <module>
from . import cuda_setup, utils, research
File "/run/media/hattivatti/StableDiffusionS/Programs/kohya_ss/venv/lib/python3.10/site-packages/bitsandbytes/research/__init__.py", line 1, in <module>
from . import nn
File "/run/media/hattivatti/StableDiffusionS/Programs/kohya_ss/venv/lib/python3.10/site-packages/bitsandbytes/research/nn/__init__.py", line 1, in <module>
from .modules import LinearFP8Mixed, LinearFP8Global
File "/run/media/hattivatti/StableDiffusionS/Programs/kohya_ss/venv/lib/python3.10/site-packages/bitsandbytes/research/nn/modules.py", line 8, in <module>
from bitsandbytes.optim import GlobalOptimManager
File "/run/media/hattivatti/StableDiffusionS/Programs/kohya_ss/venv/lib/python3.10/site-packages/bitsandbytes/optim/__init__.py", line 6, in <module>
from bitsandbytes.cextension import COMPILED_WITH_CUDA
File "/run/media/hattivatti/StableDiffusionS/Programs/kohya_ss/venv/lib/python3.10/site-packages/bitsandbytes/cextension.py", line 20, in <module>
raise RuntimeError('''
RuntimeError:
CUDA Setup failed despite GPU being available. Please run the following command to get more information:
python -m bitsandbytes
Inspect the output of the command and see if you can locate CUDA libraries. You might need to add them
to your LD_LIBRARY_PATH. If you suspect a bug, please take the information from python -m bitsandbytes
and open an issue at: https://github.com/TimDettmers/bitsandbytes/issues
Traceback (most recent call last):
File "/run/media/hattivatti/StableDiffusionS/Programs/kohya_ss/venv/bin/accelerate", line 8, in <module>
sys.exit(main())
File "/run/media/hattivatti/StableDiffusionS/Programs/kohya_ss/venv/lib/python3.10/site-packages/accelerate/commands/accelerate_cli.py", line 47, in main
args.func(args)
File "/run/media/hattivatti/StableDiffusionS/Programs/kohya_ss/venv/lib/python3.10/site-packages/accelerate/commands/launch.py", line 1017, in launch_command
simple_launcher(args)
File "/run/media/hattivatti/StableDiffusionS/Programs/kohya_ss/venv/lib/python3.10/site-packages/accelerate/commands/launch.py", line 637, in simple_launcher
raise subprocess.CalledProcessError(returncode=process.returncode, cmd=cmd)
subprocess.CalledProcessError: Command '['/run/media/hattivatti/StableDiffusionS/Programs/kohya_ss/venv/bin/python', './train_db.py', '--bucket_no_upscale', '--bucket_reso_steps=64', '--enable_bucket', '--min_bucket_reso=384', '--max_bucket_reso=1024', '--learning_rate=0.0001', '--learning_rate_te=1e-05', '--logging_dir=/run/media/hattivatti/1TBOverflow/ModelOutput/log', '--lr_scheduler=constant_with_warmup', '--lr_scheduler_num_cycles=20', '--lr_warmup_steps=178', '--max_data_loader_n_workers=0', '--resolution=512,512', '--max_train_steps=3560', '--mixed_precision=fp16', '--optimizer_type=AdamW8bit', '--output_dir=/run/media/hattivatti/1TBOverflow/ModelOutput/model', '--output_name=M00seArt', '--pretrained_model_name_or_path=/run/media/hattivatti/StableDiffusionS/Programs/stable-diffusion-webui/models/Stable-diffusion/artUniverse_v80.safetensors', '--random_crop', '--reg_data_dir=/run/media/hattivatti/1TBOverflow/ModelOutput/reg', '--save_every_n_epochs=1', '--save_model_as=safetensors', '--save_precision=fp16', '--train_batch_size=2', '--train_data_dir=/run/media/hattivatti/1TBOverflow/ModelOutput/img', '--xformers']' returned non-zero exit status 1.
Hello guys and thank you in advance. Kohya_SS doesn’t have a very active community that I can find to ask, and I can’t say how many users are Linux users anyways. I know it’s a stretch, but this was the best place I could think to ask for help. It’s worth noting that I’m a pretty nubby user, so it’s going to be really easy to talk over my head. I’ll try to give you all the relevant information, though.
Manjaro, Gnome, nvidia 1080ti, i7 4790k
Kohya_SS can be found on github and is used to train Stable Diffusion neural network stuff (to be used with Automatic1111’s version, for example). Kohya_SS requires Python 3.10 basically, so I needed to shim it with pyenv, which I successfully did, and you’ll see the confirmation of it in the images. Kohya needs a lot of other dependencies, though to work correctly. The shim I used was “pyenv local 3.10.11”
I’m no expert, but before I link everything, what I “think” is happening is that while I may have the correct stuff installed, it’s failing to path to it for some reason due to my shims or some other compatibility issues. Kohya does have a setup.sh to install all of this, and I do run it in the images below and other than not being able to configure accelerate, it has no issues (I don’t believe that detail is too relevant. I also don’t believe my card supports it due to age). And, for the record, about six months ago, I did have Kohya running fine on this exact machine, but I did have headaches getting it running then, too. Just different headaches. If you’d like to check out the repository yourself or even try installing it on your own machine, I’ll put the URL below. It seems to install fine, though. It’s only when I try to run images through it to train with, it starts screaming stuff (and the stuff is gibberish to me). I will attach it below, too. Again. Thanks in advance for any help. I will attach images and such that I believe are somehow relevant. I’m thinking the solution might involve me somehow using pip install stuff I already have installed, but in a way it can be found (since I think it’s not pathing correctly). Also, the windows subsystem library issue…I don’t think it’s really an issue. It used to do that in the past, too, and never caused me any issues for starters. I’m only pointing it out because I assume there’s a chance you’ve never used this software before.
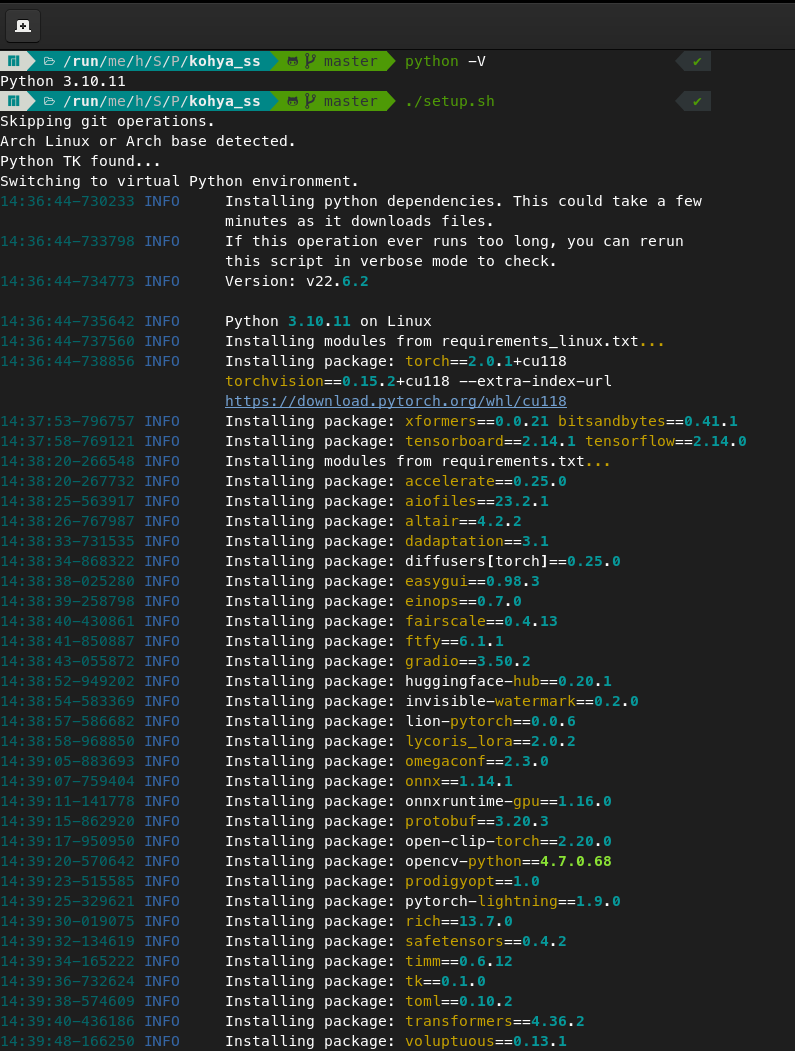
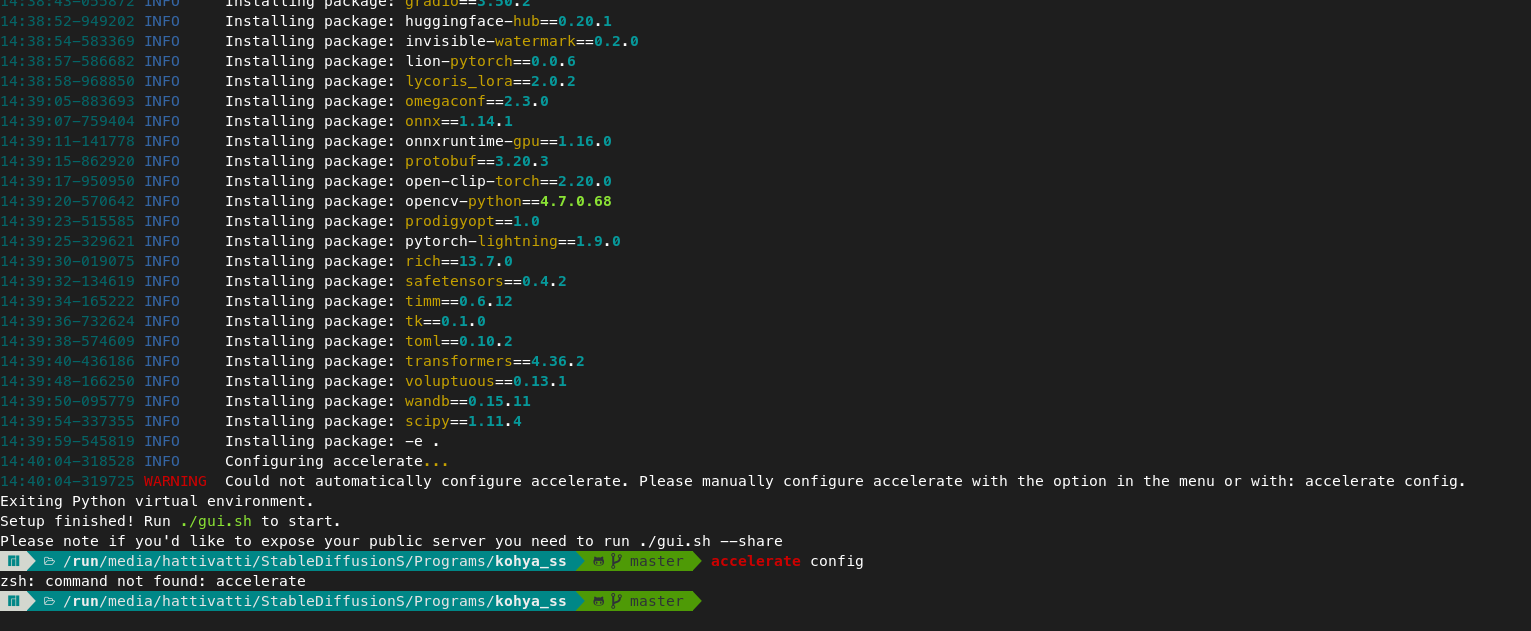
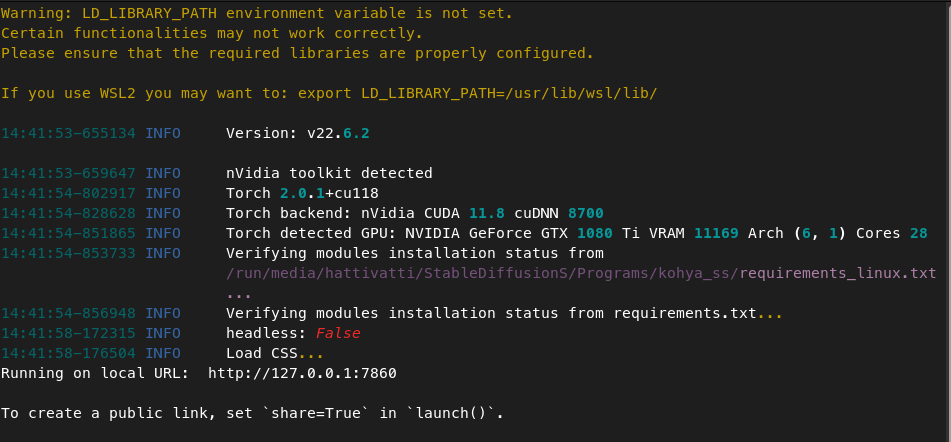
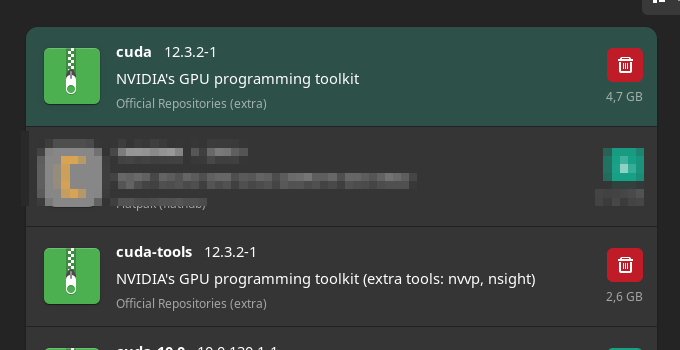

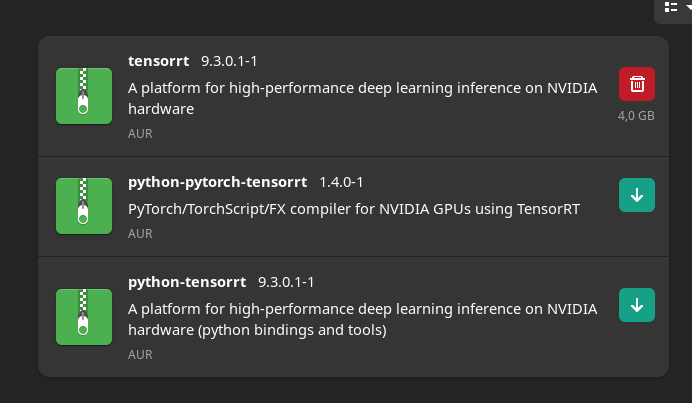
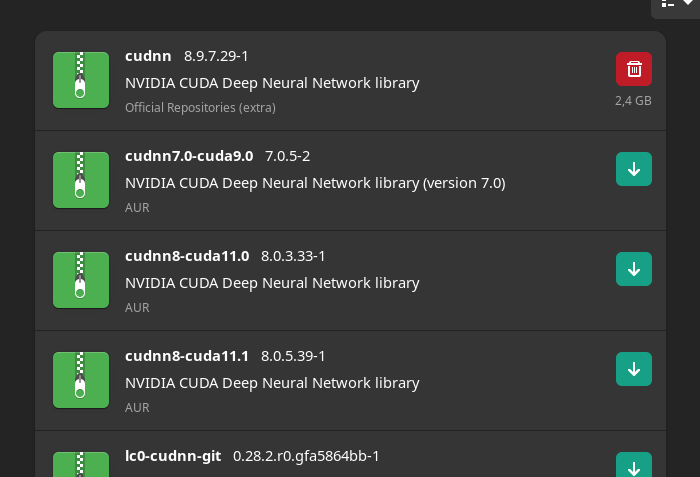
I’m sure I have some other stuff installed, too, it’s just slipping my mind. Below is the terminal output with the errors.
Warning: LD_LIBRARY_PATH environment variable is not set.
Certain functionalities may not work correctly.
Please ensure that the required libraries are properly configured.
If you use WSL2 you may want to: export LD_LIBRARY_PATH=/usr/lib/wsl/lib/
14:41:53-655134 INFO Version: v22.6.2
14:41:53-659647 INFO nVidia toolkit detected
14:41:54-802917 INFO Torch 2.0.1+cu118
14:41:54-828628 INFO Torch backend: nVidia CUDA 11.8 cuDNN 8700
14:41:54-851865 INFO Torch detected GPU: NVIDIA GeForce GTX 1080 Ti VRAM 11169 Arch (6, 1) Cores 28
14:41:54-853733 INFO Verifying modules installation status from
/run/media/hattivatti/StableDiffusionS/Programs/kohya_ss/requirements_linux.txt
...
14:41:54-856948 INFO Verifying modules installation status from requirements.txt...
14:41:58-172315 INFO headless: False
14:41:58-176504 INFO Load CSS...
Running on local URL: http://127.0.0.1:7860
To create a public link, set `share=True` in `launch()`.
14:42:52-653517 INFO Loading config...
14:42:54-365790 INFO Loading config...
14:42:56-702964 INFO Start training Dreambooth...
14:42:57-149943 INFO Valid image folder names found in:
/run/media/hattivatti/1TBOverflow/ModelOutput/img
14:42:57-151364 INFO Valid image folder names found in:
/run/media/hattivatti/1TBOverflow/ModelOutput/reg
14:42:57-297532 INFO Folder 2_M00seArt art style : steps 178
14:42:57-298694 INFO Regularisation images are used... Will double the number of steps required...
14:42:57-299618 INFO max_train_steps (178 / 2 / 1 * 20 * 2) = 3560
14:42:57-300604 INFO stop_text_encoder_training = 0
14:42:57-301416 INFO lr_warmup_steps = 178
14:42:57-303139 INFO Saving training config to
/run/media/hattivatti/1TBOverflow/ModelOutput/model/M00seArt_20240302-144257.js
on...
14:42:57-326375 INFO accelerate launch --num_cpu_threads_per_process=2 "./train_db.py"
--bucket_no_upscale --bucket_reso_steps=64 --enable_bucket
--min_bucket_reso=384 --max_bucket_reso=1024 --learning_rate="0.0001"
--learning_rate_te="1e-05"
--logging_dir="/run/media/hattivatti/1TBOverflow/ModelOutput/log"
--lr_scheduler="constant_with_warmup" --lr_scheduler_num_cycles="20"
--lr_warmup_steps="178" --max_data_loader_n_workers="0" --resolution="512,512"
--max_train_steps="3560" --mixed_precision="fp16" --optimizer_type="AdamW8bit"
--output_dir="/run/media/hattivatti/1TBOverflow/ModelOutput/model"
--output_name="M00seArt"
--pretrained_model_name_or_path="/run/media/hattivatti/StableDiffusionS/Program
s/stable-diffusion-webui/models/Stable-diffusion/artUniverse_v80.safetensors"
--random_crop
--reg_data_dir="/run/media/hattivatti/1TBOverflow/ModelOutput/reg"
--save_every_n_epochs="1" --save_model_as=safetensors --save_precision="fp16"
--train_batch_size="2"
--train_data_dir="/run/media/hattivatti/1TBOverflow/ModelOutput/img" --xformers
The following values were not passed to `accelerate launch` and had defaults used instead:
`--num_processes` was set to a value of `1`
`--num_machines` was set to a value of `1`
`--mixed_precision` was set to a value of `'no'`
`--dynamo_backend` was set to a value of `'no'`
To avoid this warning pass in values for each of the problematic parameters or run `accelerate config`.
2024-03-02 14:43:01.723671: E tensorflow/compiler/xla/stream_executor/cuda/cuda_dnn.cc:9342] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered
2024-03-02 14:43:01.723703: E tensorflow/compiler/xla/stream_executor/cuda/cuda_fft.cc:609] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered
2024-03-02 14:43:01.723731: E tensorflow/compiler/xla/stream_executor/cuda/cuda_blas.cc:1518] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
2024-03-02 14:43:01.729252: I tensorflow/core/platform/cpu_feature_guard.cc:182] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations.
To enable the following instructions: AVX2 FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.
2024-03-02 14:43:02.555114: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT
2024-03-02 14:43:03 INFO prepare tokenizer train_util.py:3959
INFO prepare images. train_util.py:1469
INFO found directory train_util.py:1432
/run/media/hattivatti/1TBOverflow/ModelOutput/img/2_M00s
eArt art style contains 89 image files
WARNING No caption file found for 89 images. Training will train_util.py:1459
continue without captions for these images. If class
token exists, it will be used. /
89枚の画像にキャプションファイルが見つかりませんでした。
これらの画像についてはキャプションなしで学習を続行します
。class tokenが存在する場合はそれを使います。
WARNING /run/media/hattivatti/1TBOverflow/ModelOutput/img/2_M00s train_util.py:1466
eArt art style/1.png
WARNING /run/media/hattivatti/1TBOverflow/ModelOutput/img/2_M00s train_util.py:1466
eArt art style/10.png
WARNING /run/media/hattivatti/1TBOverflow/ModelOutput/img/2_M00s train_util.py:1466
eArt art style/11.png
WARNING /run/media/hattivatti/1TBOverflow/ModelOutput/img/2_M00s train_util.py:1466
eArt art style/12.png
WARNING /run/media/hattivatti/1TBOverflow/ModelOutput/img/2_M00s train_util.py:1466
eArt art style/13.png
WARNING /run/media/hattivatti/1TBOverflow/ModelOutput/img/2_M00s train_util.py:1464
eArt art style/14.png... and 84 more
INFO found directory train_util.py:1432
/run/media/hattivatti/1TBOverflow/ModelOutput/reg/1_art
style contains 254 image files
WARNING No caption file found for 254 images. Training will train_util.py:1459
continue without captions for these images. If class
token exists, it will be used. /
254枚の画像にキャプションファイルが見つかりませんでした
。これらの画像についてはキャプションなしで学習を続行しま
す。class tokenが存在する場合はそれを使います。
2024-03-02 14:43:04 WARNING /run/media/hattivatti/1TBOverflow/ModelOutput/reg/1_art train_util.py:1466
style/00000-1214595497.png
WARNING /run/media/hattivatti/1TBOverflow/ModelOutput/reg/1_art train_util.py:1466
style/00001-2130368021.png
WARNING /run/media/hattivatti/1TBOverflow/ModelOutput/reg/1_art train_util.py:1466
style/00002-1697800000.png
WARNING /run/media/hattivatti/1TBOverflow/ModelOutput/reg/1_art train_util.py:1466
style/00008-3720950371.png
WARNING /run/media/hattivatti/1TBOverflow/ModelOutput/reg/1_art train_util.py:1466
style/00010-3011843286.png
WARNING /run/media/hattivatti/1TBOverflow/ModelOutput/reg/1_art train_util.py:1464
style/00011-3011843287.png... and 249 more
INFO 178 train images with repeating. train_util.py:1508
INFO 254 reg images. train_util.py:1511
WARNING some of reg images are not used / train_util.py:1513
正則化画像の数が多いので、一部使用されない正則化画像があ
ります
INFO [Dataset 0] config_util.py:544
batch_size: 2
resolution: (512, 512)
enable_bucket: True
network_multiplier: 1.0
min_bucket_reso: 384
max_bucket_reso: 1024
bucket_reso_steps: 64
bucket_no_upscale: True
[Subset 0 of Dataset 0]
image_dir:
"/run/media/hattivatti/1TBOverflow/ModelOutput/img/2_M00
seArt art style"
image_count: 89
num_repeats: 2
shuffle_caption: False
keep_tokens: 0
keep_tokens_separator:
caption_dropout_rate: 0.0
caption_dropout_every_n_epoches: 0
caption_tag_dropout_rate: 0.0
caption_prefix: None
caption_suffix: None
color_aug: False
flip_aug: False
face_crop_aug_range: None
random_crop: True
token_warmup_min: 1,
token_warmup_step: 0,
is_reg: False
class_tokens: M00seArt art style
caption_extension: .caption
[Subset 1 of Dataset 0]
image_dir:
"/run/media/hattivatti/1TBOverflow/ModelOutput/reg/1_art
style"
image_count: 254
num_repeats: 1
shuffle_caption: False
keep_tokens: 0
keep_tokens_separator:
caption_dropout_rate: 0.0
caption_dropout_every_n_epoches: 0
caption_tag_dropout_rate: 0.0
caption_prefix: None
caption_suffix: None
color_aug: False
flip_aug: False
face_crop_aug_range: None
random_crop: True
token_warmup_min: 1,
token_warmup_step: 0,
is_reg: True
class_tokens: art style
caption_extension: .caption
INFO [Dataset 0] config_util.py:550
INFO loading image sizes. train_util.py:794
100%|████████████████████████████████████████████████████████████████| 267/267 [00:01<00:00, 201.08it/s]
2024-03-02 14:43:05 INFO make buckets train_util.py:800
WARNING min_bucket_reso and max_bucket_reso are ignored if train_util.py:817
bucket_no_upscale is set, because bucket reso is defined
by image size automatically /
bucket_no_upscaleが指定された場合は、bucketの解像度は画像
サイズから自動計算されるため、min_bucket_resoとmax_bucket
_resoは無視されます
INFO number of images (including repeats) / train_util.py:846
各bucketの画像枚数(繰り返し回数を含む)
INFO bucket 0: resolution (512, 512), count: 356 train_util.py:851
INFO mean ar error (without repeats): 0.0 train_util.py:856
INFO prepare accelerator train_db.py:101
accelerator device: cuda
INFO loading model for process 0/1 train_util.py:4111
INFO load StableDiffusion checkpoint: train_util.py:4066
/run/media/hattivatti/StableDiffusionS/Programs/stable-d
iffusion-webui/models/Stable-diffusion/artUniverse_v80.s
afetensors
INFO UNet2DConditionModel: 64, 8, 768, False, False original_unet.py:1387
2024-03-02 14:43:13 INFO loading u-net: <All keys matched successfully> model_util.py:1009
INFO loading vae: <All keys matched successfully> model_util.py:1017
2024-03-02 14:43:15 INFO loading text encoder: <All keys matched successfully> model_util.py:1074
INFO Enable xformers for U-Net train_util.py:2529
prepare optimizer, data loader etc.
False
===================================BUG REPORT===================================
/run/media/hattivatti/StableDiffusionS/Programs/kohya_ss/venv/lib/python3.10/site-packages/bitsandbytes/cuda_setup/main.py:166: UserWarning: Welcome to bitsandbytes. For bug reports, please run
python -m bitsandbytes
warn(msg)
================================================================================
The following directories listed in your path were found to be non-existent: {PosixPath('/run/media/hattivatti/StableDiffusionS/Programs/kohya_ss/venv/lib/python3.10/site-packages/cv2/../../lib64')}
/run/media/hattivatti/StableDiffusionS/Programs/kohya_ss/venv/lib/python3.10/site-packages/bitsandbytes/cuda_setup/main.py:166: UserWarning: /run/media/hattivatti/StableDiffusionS/Programs/kohya_ss/venv/lib/python3.10/site-packages/cv2/../../lib64: did not contain ['libcudart.so', 'libcudart.so.11.0', 'libcudart.so.12.0'] as expected! Searching further paths...
warn(msg)
The following directories listed in your path were found to be non-existent: {PosixPath('@/tmp/.ICE-unix/1406,unix/hattivatti-tietokone'), PosixPath('local/hattivatti-tietokone')}
The following directories listed in your path were found to be non-existent: {PosixPath('-ccbin /opt/cuda/bin')}
The following directories listed in your path were found to be non-existent: {PosixPath('/sys/fs/cgroup/user.slice/user-1000.slice/user@1000.service/app.slice/app-dbus\\x2d'), PosixPath('1.2\\x2dorg.gnome.Nautilus.slice/dbus-'), PosixPath('1.2-org.gnome.Nautilus@0.service/memory.pressure')}
The following directories listed in your path were found to be non-existent: {PosixPath('/org/gnome/Terminal/screen/5405e7e9_4024_4569_b4e1_387ee2380c8d')}
The following directories listed in your path were found to be non-existent: {PosixPath('//debuginfod.archlinux.org'), PosixPath('https')}
CUDA_SETUP: WARNING! libcudart.so not found in any environmental path. Searching in backup paths...
The following directories listed in your path were found to be non-existent: {PosixPath('/usr/local/cuda/lib64')}
DEBUG: Possible options found for libcudart.so: set()
CUDA SETUP: PyTorch settings found: CUDA_VERSION=118, Highest Compute Capability: 6.1.
CUDA SETUP: To manually override the PyTorch CUDA version please see:https://github.com/TimDettmers/bitsandbytes/blob/main/how_to_use_nonpytorch_cuda.md
/run/media/hattivatti/StableDiffusionS/Programs/kohya_ss/venv/lib/python3.10/site-packages/bitsandbytes/cuda_setup/main.py:166: UserWarning: WARNING: Compute capability < 7.5 detected! Only slow 8-bit matmul is supported for your GPU! If you run into issues with 8-bit matmul, you can try 4-bit quantization: https://huggingface.co/blog/4bit-transformers-bitsandbytes
warn(msg)
CUDA SETUP: Loading binary /run/media/hattivatti/StableDiffusionS/Programs/kohya_ss/venv/lib/python3.10/site-packages/bitsandbytes/libbitsandbytes_cuda118_nocublaslt.so...
libcusparse.so.11: cannot open shared object file: No such file or directory
CUDA SETUP: Problem: The main issue seems to be that the main CUDA runtime library was not detected.
CUDA SETUP: Solution 1: To solve the issue the libcudart.so location needs to be added to the LD_LIBRARY_PATH variable
CUDA SETUP: Solution 1a): Find the cuda runtime library via: find / -name libcudart.so 2>/dev/null
CUDA SETUP: Solution 1b): Once the library is found add it to the LD_LIBRARY_PATH: export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:FOUND_PATH_FROM_1a
CUDA SETUP: Solution 1c): For a permanent solution add the export from 1b into your .bashrc file, located at ~/.bashrc
CUDA SETUP: Solution 2: If no library was found in step 1a) you need to install CUDA.
CUDA SETUP: Solution 2a): Download CUDA install script: wget https://github.com/TimDettmers/bitsandbytes/blob/main/cuda_install.sh
CUDA SETUP: Solution 2b): Install desired CUDA version to desired location. The syntax is bash cuda_install.sh CUDA_VERSION PATH_TO_INSTALL_INTO.
CUDA SETUP: Solution 2b): For example, "bash cuda_install.sh 113 ~/local/" will download CUDA 11.3 and install into the folder ~/local
Traceback (most recent call last):
File "/run/media/hattivatti/StableDiffusionS/Programs/kohya_ss/./train_db.py", line 504, in <module>
train(args)
File "/run/media/hattivatti/StableDiffusionS/Programs/kohya_ss/./train_db.py", line 180, in train
_, _, optimizer = train_util.get_optimizer(args, trainable_params)
File "/run/media/hattivatti/StableDiffusionS/Programs/kohya_ss/library/train_util.py", line 3616, in get_optimizer
import bitsandbytes as bnb
File "/run/media/hattivatti/StableDiffusionS/Programs/kohya_ss/venv/lib/python3.10/site-packages/bitsandbytes/__init__.py", line 6, in <module>
from . import cuda_setup, utils, research
File "/run/media/hattivatti/StableDiffusionS/Programs/kohya_ss/venv/lib/python3.10/site-packages/bitsandbytes/research/__init__.py", line 1, in <module>
from . import nn
File "/run/media/hattivatti/StableDiffusionS/Programs/kohya_ss/venv/lib/python3.10/site-packages/bitsandbytes/research/nn/__init__.py", line 1, in <module>
from .modules import LinearFP8Mixed, LinearFP8Global
File "/run/media/hattivatti/StableDiffusionS/Programs/kohya_ss/venv/lib/python3.10/site-packages/bitsandbytes/research/nn/modules.py", line 8, in <module>
from bitsandbytes.optim import GlobalOptimManager
File "/run/media/hattivatti/StableDiffusionS/Programs/kohya_ss/venv/lib/python3.10/site-packages/bitsandbytes/optim/__init__.py", line 6, in <module>
from bitsandbytes.cextension import COMPILED_WITH_CUDA
File "/run/media/hattivatti/StableDiffusionS/Programs/kohya_ss/venv/lib/python3.10/site-packages/bitsandbytes/cextension.py", line 20, in <module>
raise RuntimeError('''
RuntimeError:
CUDA Setup failed despite GPU being available. Please run the following command to get more information:
python -m bitsandbytes
Inspect the output of the command and see if you can locate CUDA libraries. You might need to add them
to your LD_LIBRARY_PATH. If you suspect a bug, please take the information from python -m bitsandbytes
and open an issue at: https://github.com/TimDettmers/bitsandbytes/issues
Traceback (most recent call last):
File "/run/media/hattivatti/StableDiffusionS/Programs/kohya_ss/venv/bin/accelerate", line 8, in <module>
sys.exit(main())
File "/run/media/hattivatti/StableDiffusionS/Programs/kohya_ss/venv/lib/python3.10/site-packages/accelerate/commands/accelerate_cli.py", line 47, in main
args.func(args)
File "/run/media/hattivatti/StableDiffusionS/Programs/kohya_ss/venv/lib/python3.10/site-packages/accelerate/commands/launch.py", line 1017, in launch_command
simple_launcher(args)
File "/run/media/hattivatti/StableDiffusionS/Programs/kohya_ss/venv/lib/python3.10/site-packages/accelerate/commands/launch.py", line 637, in simple_launcher
raise subprocess.CalledProcessError(returncode=process.returncode, cmd=cmd)
subprocess.CalledProcessError: Command '['/run/media/hattivatti/StableDiffusionS/Programs/kohya_ss/venv/bin/python', './train_db.py', '--bucket_no_upscale', '--bucket_reso_steps=64', '--enable_bucket', '--min_bucket_reso=384', '--max_bucket_reso=1024', '--learning_rate=0.0001', '--learning_rate_te=1e-05', '--logging_dir=/run/media/hattivatti/1TBOverflow/ModelOutput/log', '--lr_scheduler=constant_with_warmup', '--lr_scheduler_num_cycles=20', '--lr_warmup_steps=178', '--max_data_loader_n_workers=0', '--resolution=512,512', '--max_train_steps=3560', '--mixed_precision=fp16', '--optimizer_type=AdamW8bit', '--output_dir=/run/media/hattivatti/1TBOverflow/ModelOutput/model', '--output_name=M00seArt', '--pretrained_model_name_or_path=/run/media/hattivatti/StableDiffusionS/Programs/stable-diffusion-webui/models/Stable-diffusion/artUniverse_v80.safetensors', '--random_crop', '--reg_data_dir=/run/media/hattivatti/1TBOverflow/ModelOutput/reg', '--save_every_n_epochs=1', '--save_model_as=safetensors', '--save_precision=fp16', '--train_batch_size=2', '--train_data_dir=/run/media/hattivatti/1TBOverflow/ModelOutput/img', '--xformers']' returned non-zero exit status 1.
Captions are also not required, if that bit is catching your eye. I see it warning about it, but I’m quite confident something else here is causing the issue.