Should i change the kernel perhaps? I mean, if the file system is ok, maybe the kernel is having issues…
I don’t think the kernel caused the issue.
I still doubt hardware is the issue. In my past, my NEW RAM was faulty, thanks to Btrfs to detect my corrupted files. No need expensive ECC RAM
1 Like
Well it happened once or twice before too, one time i had to take ownership of some folder that was responsible for some KDE functionality, it randomly lost permissions, and i did get new RAM, but it happened before new ram as well…
What should i do then?
I’d hate to randomly lose data - though, this seems unlikely, but still…
I see, Btrfs changed your whole system to read-only automatically when it detected some corrupted data. That is good as alarm to notice you immediately. It stops writing your data further, otherwise it will get more corruptions.
You have experienced this issue twice or more, it seems no coincidence, your hardware is probably the issue.
Now your data is ok after scrub, you need to backup first! Then check your hardware later.
What exactly though? The nvme drive? And how?
EDIT:
smartctl shows drive health is fine:
smartctl 7.3 2022-02-28 r5338 [x86_64-linux-6.1.4-x64v1-xanmod1-MANJARO] (local build)
Copyright (C) 2002-22, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF SMART DATA SECTION ===
SMART overall-health self-assessment test result: PASSED
smartctl 7.3 2022-02-28 r5338 [x86_64-linux-6.1.4-x64v1-xanmod1-MANJARO] (local build)
Copyright (C) 2002-22, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Number: KINGSTON SNV2S500G
Serial Number: 50026B7282DB8CBD
Firmware Version: SBI02102
PCI Vendor/Subsystem ID: 0x2646
IEEE OUI Identifier: 0x0026b7
Controller ID: 1
NVMe Version: 1.4
Number of Namespaces: 1
Namespace 1 Size/Capacity: 500.107.862.016 [500 GB]
Namespace 1 Formatted LBA Size: 512
Namespace 1 IEEE EUI-64: 0026b7 282db8cbd5
Local Time is: Wed Jan 18 21:35:34 2023 CET
Firmware Updates (0x12): 1 Slot, no Reset required
Optional Admin Commands (0x0016): Format Frmw_DL Self_Test
Optional NVM Commands (0x009f): Comp Wr_Unc DS_Mngmt Wr_Zero Sav/Sel_Feat Verify
Log Page Attributes (0x12): Cmd_Eff_Lg Pers_Ev_Lg
Maximum Data Transfer Size: 64 Pages
Warning Comp. Temp. Threshold: 83 Celsius
Critical Comp. Temp. Threshold: 90 Celsius
Supported Power States
St Op Max Active Idle RL RT WL WT Ent_Lat Ex_Lat
0 + 5.00W - - 0 0 0 0 0 0
1 + 3.50W - - 1 1 1 1 0 200
2 + 2.50W - - 2 2 2 2 0 1000
3 - 1.50W - - 3 3 3 3 5000 5000
4 - 1.50W - - 4 4 4 4 20000 70000
Supported LBA Sizes (NSID 0x1)
Id Fmt Data Metadt Rel_Perf
0 + 512 0 0
=== START OF SMART DATA SECTION ===
SMART overall-health self-assessment test result: PASSED
SMART/Health Information (NVMe Log 0x02)
Critical Warning: 0x00
Temperature: 34 Celsius
Available Spare: 100%
Available Spare Threshold: 10%
Percentage Used: 0%
Data Units Read: 4.960.365 [2,53 TB]
Data Units Written: 4.659.067 [2,38 TB]
Host Read Commands: 39.270.944
Host Write Commands: 44.658.307
Controller Busy Time: 4.503
Power Cycles: 144
Power On Hours: 891
Unsafe Shutdowns: 3
Media and Data Integrity Errors: 0
Error Information Log Entries: 0
Warning Comp. Temperature Time: 0
Critical Comp. Temperature Time: 0
Error Information (NVMe Log 0x01, 16 of 64 entries)
No Errors Logged
There are different methods of testing hardware:
How to test your RAM:
-
Take out all RAM from your mainboard and test each individual RAM with
mprimeormemtestto see which one is faulty. -
If all RAM are fine after testing, your disk or mainboard (bus system) is probably faulty.
Can’t memtest check both at the same time? Like, each individually?
Well, disk is fine…
I’ll test RAM tomorrow, i still need the computer today for some things.
![]() keep on seeking, and you will find; https://wol.jw.org/en/wol/b/r1/lp-e/nwtsty/42/11#s=9&study=discover
keep on seeking, and you will find; https://wol.jw.org/en/wol/b/r1/lp-e/nwtsty/42/11#s=9&study=discover
Please have a look at:
to see what RAM could do.
It is easy to blame btrfs ![]()
BUT btrfs detects such errors. Other filesystems don´t.
I’m not blaming btrfs for anything, it was just my first guess. ![]()
I will run memtest tomorrow, since i still need to work on the computer. For now it probably won’t fail.
I use Ext4 as a stable filesystem for my 2 main storage HDD’s, but I had BTRFS on my 10 year old Western Digital 2TB drive with movie archives.
BTRFS is great for my system SSD for a couple of reasons:
- Instant snapshots
- I run back-in-time rsync backups.
This means stability, if my SSD takes a bullet, I can buy a new one, reinstall and restore from back-in-time.
If I edit my passwd file and can’t log in, I can reboot and select a snapshot.
I switched after Timeshift had issues restoring rsync backups and I ended up reinstalling anyway - I don’t know if the parse list was just too long or what, but it kept failing with my exisiting snapshots… Thankfully, rsync snapshots are available on disk to be copied to a new installation.
I don’t have an exotic config, and encountered zero issues so far.
1 Like
It can do, but it does not tell you which of the two is bad after test result.
Note:
memtest has the limit and can not detect some errors of RAM when:
- DMA transfer under certain circumstances.
- Probability of bit error is low like random (One time test is not enough, you need repeat test more than 10 times.) It is related to:
- Temperature
- Humidity
- EMI
- Voltage stability
- Some external factor …
In my past, memtest did not help me to detect a random 1-bit error in my failing RAM, but Btrfs did.
How did I find my faulty RAM without using memtest:
I tested every single RAM and created any big file zip 20 GB, then copied it to other partition in the same disk more than 10 times repeats , then checked each file with checksum e.g SHA1 or SHA256 more than 10 times repeats, if all checksum results match correctly:
$ sha256sum 20GB_File
One of 4 RAMs showed up the error, rest others have no issue. That is why I caught the faulty RAM.
1 Like
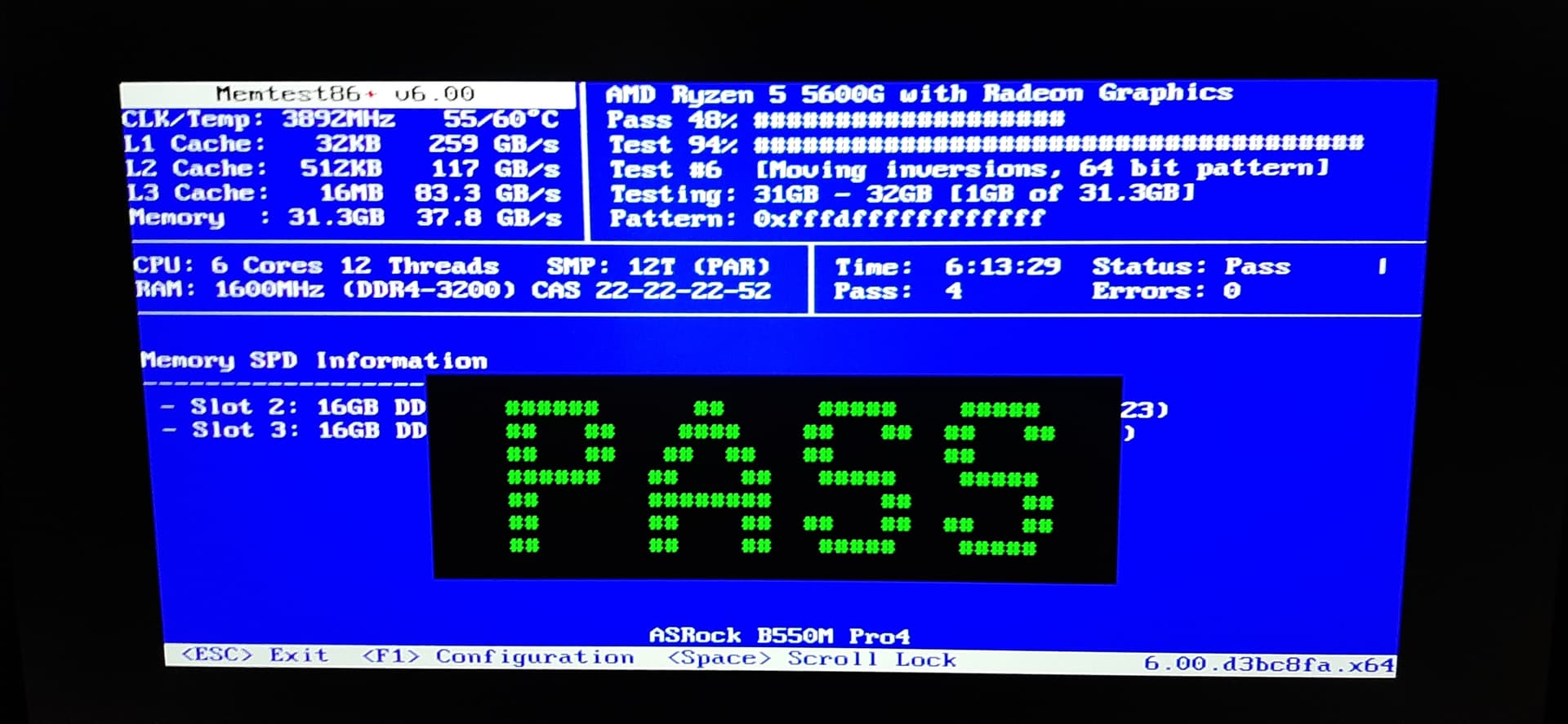
Well, memtest ran for 6 hours, 4 passes, 0 errors… I know i didn’t test each stick individually, but if any were showing errors, then i’d decouple them and find out which one it is. Both seem fine so i don’t think i have to do that.
Now what? How do i test mainboard bus system?
Try to install mprime-bin from AUR
https://wiki.archlinux.org/title/Stress_testing
If no error then just use back normal until btrfs-desktop-notification-git helps you notice when new Btrfs warn or error message pops up.
journalctl-desktop-notification-git does the same and is general to everyone .
But btrfs-desktop-notification-git is special for btrfs only.
Ok, thanks, i’ll try it.
Well, i ran the stress test for a while, didn’t seem to be any issues whatsoever…
Weird.
Which stress test did you run, and how?
Also, an obvious thing has been pointed to you early in the thread
At some point stop ignoring the first thing you should have tried:
INSTALL A MANJARO KERNEL NOW
When you’ll have done extensive tests with what comes with Manjaro, and find that you continue to see the exact same problematic behavior, you can then say it is not because of you external modified kernel that you see issues apparently only you have here on the forum.
Use logic it helps not wasting time. It may not be that, but why are you forcefully ignoring that obvious thing, I can’t tell…
You need to trim the big pieces first before detailing.
4 Likes
mprime-bin, left it on default options for half an hour, didn’t report any issues.
I’m not comfortable leaving stress tests on for longer so i stopped it.
I asked in this thread if it’s kernel related, people have told me no, so i didn’t.
But yeah, i guess i can try it.
No need to shout. ![]()
I’m definitely not the only one having issues with this, and this was on an official Manjaro kernel, though, granted, an older one. It was perfectly safe to assume the custom kernel wasn’t at fault here.
This exact thread actually solved one of the issues when this happened before. When some folder became not writeable due to permissions changing for no reason.
Because it’s not obvious it’s the kernel. I’m perfectly happy testing the normal one, but all evidence pointed to it not being the case, as others have stated here as well.
To me as it is not from Manjaro, and heavily modified ‘tuned’ kernel, to me this is obvious to go back with default kernel to rule that out.
Do Large FTT test for the RAM with mprime if you have an error you have a RAM issue.
I switched to the default kernel, we’ll see. I won’t switch back to xanmod if everything works fine from now on.
I tested memory with memtest for 6 hours, if any of the modules were faulty i the error would probably show by then. But i guess i can do one more, but later, need my computer now.
Asking back a week later to see if you had time to do more tests and check if you have same issue with Manjaro kernel? Any news?
2 Likes