That was fun! Let’s wipe all your data and do it all over again! 
You can use whichever way you want to identify your block devices.
- Kernel-assigned
- Located directly under /dev/
- Familiar naming-scheme
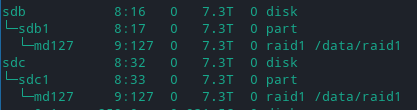
- Devices: sda, sdb, sdc, nvme0n1, nvme1n1
- Partitions: sda1, sda2, sda3, sdb1, sdc1, nvme0n1p1, nvme0n1p2, nvme1n1p1
- While not often, these can change, based on the internal ports the devices are connected to, external ports, what others devices are plugged in, etc
- Unique ID, based on model and/or serial number
- Located under /dev/disk/by-id/
- Symlinks to the actual kernel-assigned names
- More meaningful, since they usually follow a pattern of recognizable brands and serial numbers
- Using the device name (without -partX) is the equivalent to using /dev/sda, /dev/sdb, etc…
- Partitions are appended to the device name with -part1, -part2, -part3, etc.
- Usually works across different computers
- Unique ID based on UUID
- Symlinks to the actual kernel-assigned names
- Each device, partition, LUKS container, logical volume, assembled array, etc, has its own unique UUID
- Can be specified with UUID=, or --uuid=, or /dev/disk/by-uuid/, etc, depending on the config or application
- Works across different computers
- Individual partition UUIDs found under /dev/disk/by-partuuid/ (not unique globally, only locally on current system)
So any method above works, for example, to assemble an array, specify an fstab entry, check a file-system, unlock and map an encrypted LUKS container, start a volume group (LVM), etc.
The point being, don’t rely on sda, sda1, sdb, sdb1, sdc, sdc1, etc, for longterm use. You can easily use lsblk and /proc/partition to try to identify your block devices, but it doesn’t hurt to look under /dev/disk/by-id/ (or use the UUIDs).
Most tools are pretty “smart” though. I believe mdadm (and LVM) can simply be told to “scan all block devices, find all md (or PV) devices, and assemble from there” without ever having to specify the exact devices needed, as long as you provide identifiable information (“name” or “uuid” of the array or logical volume group).
Remember, the UUID for the block devices are a way to specify which devices are needed to build the array, while the UUID for the array itself is akin to its “name”. Once everything is assembled, there’s a new UUID that only exists when the array is assembled, and it is this device where your ext4 file-system lives.
So yeah, you’ve got three sets of UUIDs going on: (1) the UUIDs of partitions that make up your array, (2) the UUID found in the superblock metadata of the array, (3) the UUID of the assembled array that a file-system is formatted on. All three are different and have nothing to do with each other.
EDIT: I highly recommend people get familiar with /dev/disk/by-id/
You’ll notice it “makes more sense” for your physical block devices, as it has the closest hands on naming scheme. (Some devices will be represented two or three different ways.)
Here’s a listing of mine, for example. (I’m leaving out the redundant entries.)
ls -l /dev/disk/by-id/
ata-hp_HLDS_DVDRW_GUD1N_873D2038077 -> ../../sr0
ata-Samsung_SSD_860_EVO_500GB_S8678NE1M67503F -> ../../sda
ata-Samsung_SSD_860_EVO_500GB_S8678NE1M67503F-part1 -> ../../sda1
nvme-SK_hynix_BC501_TGF342GDJGGH-8324A_NZ87645114133054F2 -> ../../nvme0n1
nvme-SK_hynix_BC501_TGF342GDJGGH-8324A_NZ87645114133054F2-part1 -> ../../nvme0n1p1
nvme-SK_hynix_BC501_TGF342GDJGGH-8324A_NZ87645114133054F2-part2 -> ../../nvme0n1p2
nvme-SK_hynix_BC501_TGF342GDJGGH-8324A_NZ87645114133054F2-part3 -> ../../nvme0n1p3
nvme-SK_hynix_BC501_TGF342GDJGGH-8324A_NZ87645114133054F2-part4 -> ../../nvme0n1p4
nvme-SK_hynix_BC501_TGF342GDJGGH-8324A_NZ87645114133054F2-part5 -> ../../nvme0n1p5
Just by looking at the above output, you can get an idea of what type of devices they are (DVD burner, SATA SSD, NVMe m.2) , what brands they are (HP, Samsung, Hynix), and what models they are. (I changed the serial number strings for privacy and warranty-related reasons.)
I can use the above strings instead of /dev/sda, /dev/sda1, /dev/nvme0n1p4, etc, since the symlinks point to the proper kernel-assigned devices, no matter how many times I reboot or change around the order of cables and ports.
However, the UUID is more permanent and is the preferred method, since it’s pretty much a 100% guarantee of never changing, no matter the reboots, no matter relocating to the new computer.