Okay, after 1-2 weeks of focusing ![]() on evaluating Manjaro KDE Plasma as my windows replacement… I’d say my evaluation has concluded that now is the time to ditch windows entirely.
on evaluating Manjaro KDE Plasma as my windows replacement… I’d say my evaluation has concluded that now is the time to ditch windows entirely.
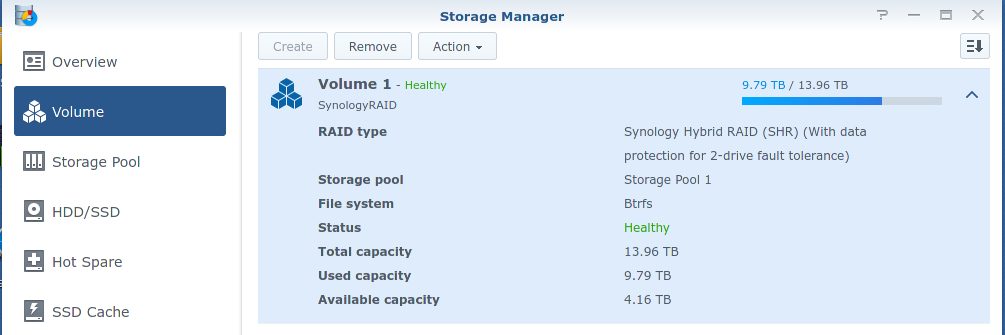
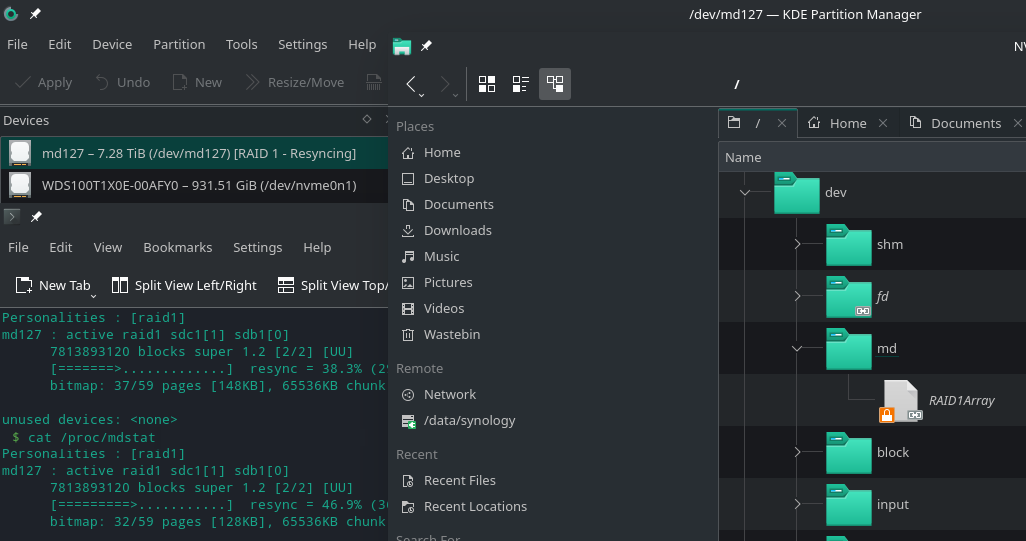
One of the only things that didn’t appear to be detected/set-up right away post Manjaro Install was the mirror built on my HighPoint HBA… Manjaro sees the two hard drives independently; not as one mirror.
$ lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
sdb 8:16 0 7.3T 0 disk
├─sdb1 8:17 0 16M 0 part
└─sdb2 8:18 0 7.3T 0 part
sdc 8:32 0 7.3T 0 disk
├─sdc1 8:33 0 16M 0 part
└─sdc2 8:34 0 7.3T 0 part
Running the inxi --admin --verbosity=7 --filter --no-host --width command shows that some (I assume ) generic driver was used…
RAID:
Hardware-1: HighPoint Device driver: mvsas v: 0.8.16 port: N/A
bus-ID: 24:00.0 chip-ID: 1103.2720 rev: 03 class-ID: 0104
Perhaps there is a setup needing to happen to get the drives to appear as one mirror under the existing driver… but then I found that HighPoint does provide a specific Linux open source driver for my HighPoint RocketRAID 2720A HBA.
There is no guarantee that even this new Driver is going to solve the mirror detection right away… but I do recall that the “WebGUI - RAID Management Interface” (also listed with the driver to install) did have a tool for importing/exporting the RAID configs… so I suspect that would force the Linux driver/tools to recognize the pre-existing mirror.
The readme contained within the driver’s tar.gz makes it sound like a simple process… but then in the notes goes on to talk about kernel development packages and kernel driver modules… topics I am no where near understanding yet…
#############################################################################
2. Installation
#############################################################################
1) Extract the source package to a temporary directory.
2) Change to the temporary directory.
3) Run the .bin file to install the driver package.
# chmod +x ./rr272x_1x-linux-src-vx.x.x-xx_xx_xx.bin
# ./rr272x_1x-linux-src-vx.x.x-xx_xx_xx.bin
or
$ sudo ./rr272x_1x-linux-src-vx.x.x-xx_xx_xx.bin
on Ubuntu system.
NOTES:
The installer requires super user's permission to run the installation.
So if you are not logged in as root, please supply the password of root to
start the installation.
The installer will check and install build tools if some of them is missing.
A network connection is required to install the build tools. The following
tools are checked by the installer:
make
gcc
perl
wget
They are installed automatically when you select "Software Development
Workstation" group in the installation of RHEL/CentOS 6.
When packages are installed from network, it may take too long to complete
the installation as it depends on the network connection. The packages could
be installed first to omit the network issue.
If the installer failed to find or install the required build tools, the
installation will be terminated without any change to the system.
The installer will install folders and files under /usr/share/hptdrv/.
And the auto build script will be invoked to download and install kernel
development package if needed and the build driver module for new kernels
automatically when system reboot or shutdown.
But I am also recalling an memory where I heard that RAID (software raid?) under Linux is very robust and stable… unlike Windows software RAID.
So my question is… if you were in my shoes and trying to decide between an HBA (which isn’t a full hardware raid card that relies on system resources… hmm, does that mean it’s a FakeRAID?) and just yanking out the HBA so you could direct connect the drives to SATA and build a Linux RAID (mirror)… what path would you choose and why?
Note 1: The data on the Mirror is not a deciding factor, as it was 100% copied over to my NAS before I installed Manjaro… reformatting the mirror as EXT4 is in the cards.
Note 2: I noticed in the driver release notes that the max kernel mentioned is 5.10… and while that is the latest LTS kernel for Manjaro today, I found better performance/stability for my AMD 5600X CPU and 6800XT GPU by moving to the 5.13 kernel… so I’m not sure if my being on 5.13 is a limitation for a driver with kernel support listed as high as 5.10, but it definitely strikes me as a concern.